- Biweekly Engineering
- Posts
- Apache Beam at LinkedIn | Biweekly Engineering - Episode 27
Apache Beam at LinkedIn | Biweekly Engineering - Episode 27
How Pinterest developed Goku - it's in-house time series database | LinkedIn's impressive effort to adopt Apache Beam
Biweekly Engineering
February 20, 2024
Hello all! 👋
Welcome to the 27th episode of the one and only 🥁 Biweekly Engineering! Today we have fantastic articles from Pinterest and LinkedIn!
Let’s read!

The mighty Niagara Falls
Goku: Pinterest’s Time-Series Database
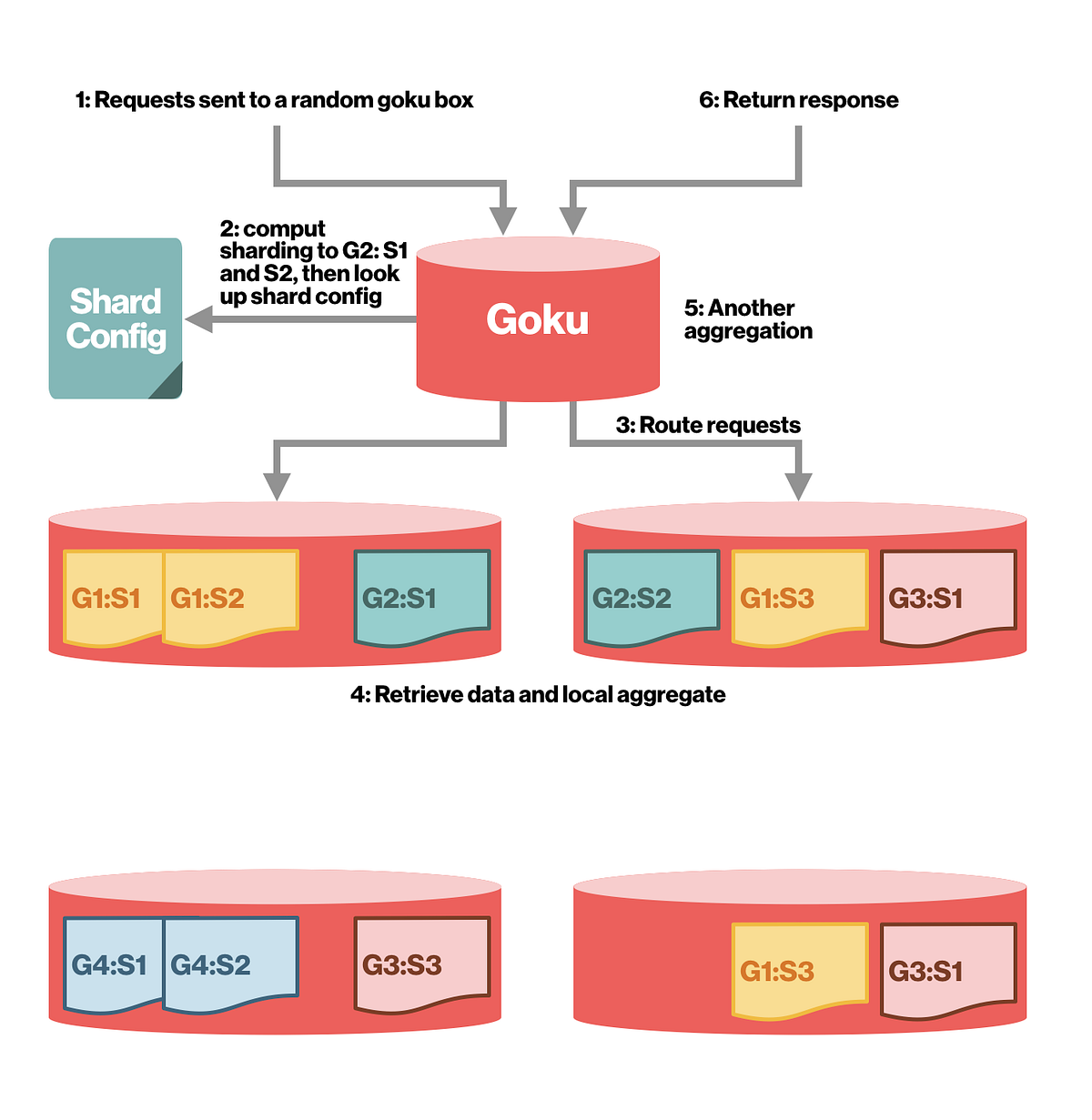
In the first article for today, Pinterest Engineering introduces us to Goku - their in-house solution for building a scalable and high-performing time series database system. Time series data is a critical component in many applications, especially those dealing with monitoring, analytics, and IoT.
Pinterest originally was using OpenTSDB for meeting its time series data needs but it came with challenges, such as scalability issues and lack of performance under heavy loads.
To address these challenges, the engineering team at Pinterest developed Goku, which offers several key features:
Scalability: Goku leverages a distributed architecture, allowing it to scale horizontally as data volumes grow, ensuring Pinterest can handle increasing demands without sacrificing performance.
High Performance: Through optimizations in storage, indexing, and querying, Goku achieves impressive performance metrics, enabling fast and efficient data retrieval even in the face of heavy workloads.
Reliability: With built-in fault tolerance mechanisms and data replication strategies, Goku ensures data integrity and reliability, crucial for maintaining Pinterest's service uptime and user experience.
In terms of architecture, the article highlights Goku's two-layer sharding strategy for distributing data across shards and its use of an inverted index to improve query performance. In the end, it shows that Goku outperforms OpenTSDB in almost all aspects and that future plans include supporting queries longer than one day and data replication.
The article was written in 2018. I am not sure what other options Pinterest considered instead of building their own database! It would be nice to get an overall idea of the considerations the made.
Nonetheless, the article is a good example of how to design a time series database.
Apache Beam at LinkedIn: A Sneak Peak

Ah, the age-old struggle: batch vs. stream processing!
As an engineer with experiences in data pipelines, I can't help but agree to the challenges laid out in this LinkedIn blog post. Maintaining separate systems for both feels like juggling chainsaws – effective, but a tad precarious.
The idea of writing unified pipelines for both batch and streaming is incredibly appealing. Reduced complexity, easier maintenance, and a potential 94% processing time cut? Hold my sharbat please!
In this article, LinkedIn shared how they used Apache Beam to unify one of their data pipelines.
The key here is Beam's ability to handle both modes with the same codebase. It's like having a Swiss Army knife for data – powerful and versatile. No more context switching, no more duplicated effort. Just clean, maintainable code that adapts to your needs.
🛑 Beware! No silver bullet exists. The article rightly mentions challenges like handling diverse data sources and ensuring data lineage. But these are solvable hurdles, and the Beam community has been constantly pushing for improvements.
Below are some key advantages of unifying your batch and streaming pipelines:
Reduced development load: Maintaining separate systems is no fun. LinkedIn had two separate pipelines for the same task, but Beam unified them and reduced development time. Also, unified pipelines mean writing code once, deploying twice. That's efficiency we can all appreciate.
Improved resource utilisation: Beam's reported 50% resource reduction is music to any cost-conscious engineer's ears.
But remember, it's not a one-size-fits-all solution:
Evaluate your use case: Not every pipeline needs unification. Assess complexity, latency requirements, and team expertise before diving in.
Beam is evolving: Keep in mind that Beam is still under development. Stay updated on the latest advancements and potential limitations.
Start small: Don't jump headfirst into a complex migration. Pilot Beam on a manageable project to gain experience and build confidence.
Overall, don’t forget to read this article if you are curious about the prospects of Apache Beam. Enjoy!
And that marks the end of today’s episode! Did you learn something new? Hopefully you did! Please continue sharing the newsletter with your peers and drive our effort of collective learning! 📖
See you all in the next one! ✌️
Reply