- Biweekly Engineering
- Posts
- The Evolution of Uber's API Gateway - Biweekly Engineering - Episode 5
The Evolution of Uber's API Gateway - Biweekly Engineering - Episode 5
Articles from Uber, Sam Newman, and Fahim ul Haq
Biweekly Engineering
January 06, 2023
Bienvenue people! Hope you had a wonderful new year celebration for this brand new beginning. Here I am again, back with the first issue of Biweekly Engineering in 2023!
Before starting, let me quickly share one of my few new year resolutions. In this year, I want to remain consistent and keep writing this newsletter, and hope for the newsletter to grow. :)
So without further ado, let's begin.

The Pyramid at the Louvre Museum
The evolution of Uber's API gateway

#uber #apigateway #microservices
API gateway is a popular architectural pattern where a service (or a bunch of services) is built as a gatekeeper for the internal systems. An API gateway can have a variety of responsibilities, but the fundamental one is to manage the APIs of the system. Any client who tries to reach your API would need to hit your API gateway. The gateway will handle the request accordingly by forwarding it to relevant backend services behind it.
Like many other startups, Uber started with a more monolithic-like architecture. It resulted in a state where the system didn't have a true API gateway but a functionality in the dispatch service (the system where drivers and riders connect) to route requests based on a field in the request body named messageType.
Over the years, Uber evolved to a microservices-based system consisting of a staggering number of 2200+ microservices. As a part of this massive evolution, Uber built a second-generation API gateway. It was a Node.js system serving 800k requests per second.
But as we can expect, the second-generation system also had some shortcomings. The system became too big with a monorepo of 40+ services, 50k tests were running on every new change, and upgrading npm libraries became very difficult. On the other hand, Uber adopted Go and Java more, and gRPC became the protocol of choice. In summary, a third generation of the API gateway was called-for.
In the article, we get a thorough overview of the evolution of Uber's gateway, from a first-generation monolithic-like gateway functionality to a third-generation edge layer - a gateway system which makes the most sense.
The Backends for Frontends (BFF) architecture pattern in the microservices world
#microservices #bff #microservicepattern
In our next topic for today, we will share a fairly new architectural pattern in the microservices world - the Backends for Frontends (BFF) pattern.
So what does it mean? Imagine you have a website that sells books. There is an API gateway that receives requests from the clients (in this case, web browsers) and responds with data required to render a page on the website. This is fine as long as you are only dealing with one type of client (web browsers).
Over time, your business grew bigger. You now have a mobile app, both for iOS and Android. You also have a mobile browser version of the website. There are now a variety of clients in your business, and all of them don't need the same set of data to render a page.
To put this in a better perspective, think of an app that is also usable on a browser from your computer. Most likely, you do not see the same set of features on the app compared to the web.
For a large system with different clients, it eventually becomes difficult to handle them using a generic gateway layer. What if you have a separate microservice for each different group of clients that sits between the clients and the backend systems? This is what BFF suggests.
BFF was initially proposed by Sam Newman, the article author himself. This pattern promotes the idea of more controlled and granular UI rendering powered by backend systems. Here, the BFF layer is powering up the frontend layer by fetching required data from the core backend services behind it.
How traffic spike crashed Ticketmaster - a discussion
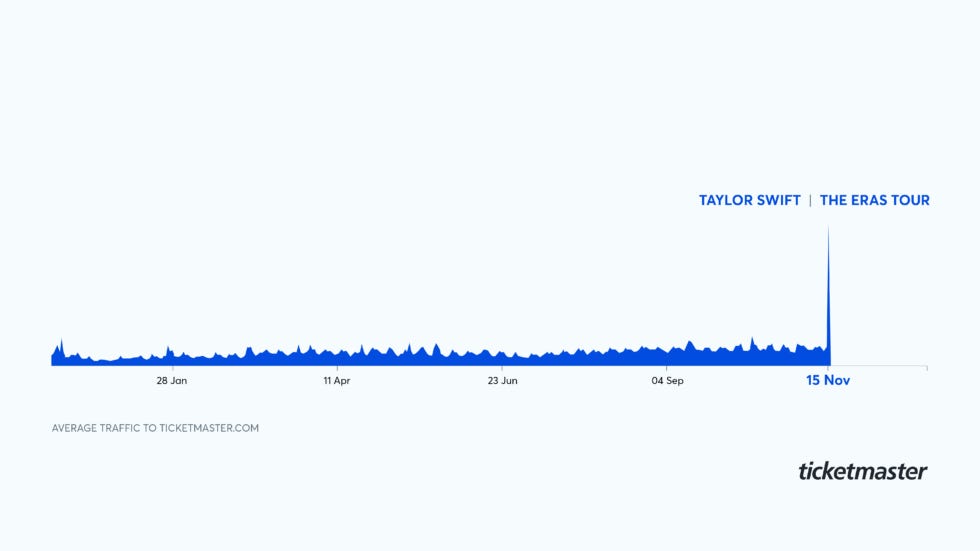
#ticketmaster #trafficspike #scalability
Recently, due to a traffic spike for selling Taylor Swift concert tickets, Ticketmaster crashed - leaving many users disappointed with the platform. The article is not an engineering blog post from Ticketmaster. I couldn't find one, so I shared a discussion by Fahim ul Haq, the co-founder of Educative Inc.
In short, Ticketmaster has a system called Verified Fans, to differentiate between actual people willing to buy tickets from bots. The company wanted to presell tickets for the Taylor Swift concert. More than 3 million fans registered for the presale. Passcodes were provided to 1.5 million users and 2 million were waitlisted.
Those 1.5 million users were invited to buy tickets, and Ticketmaster was prepared for this amount of traffic. But 14 million users wanted to buy ticket creating an unmanageable amount of traffic.
Ideally, we would expect that the system would reject requests when the capacity is full. But the Ticketmaster system failed to do so. Hence, the crash.
The crash meant many users couldn't buy tickets even though they were invited and had valid passcodes.
The article gives us an overview of what might have gone wrong and how the mishap could be prevented. Incidents like these are fairly common in the tech world. Every company faces such outages in their lifetime. Engineers try to learn from such outages and avoid the same potholes that would cause similar issues. I will discuss more on how incident management is done in the real world in a future issue.
That would be all for today. Hope you could learn something from the discussion. Have a great weekend, and see you all in two weeks!
Reply