- Biweekly Engineering
- Posts
- Building Effective Agents - Lessons from Anthropic | Biweekly Engineering - Episode 37
Building Effective Agents - Lessons from Anthropic | Biweekly Engineering - Episode 37
What Anthropic learned from its customers on building AI agent-based architecture
Biweekly Engineering
January 31, 2025
At the end of 2024, a lot of discussion sparked on what’s next for AI?
A common narration appeared in the AI world over the past year, including from Anthropic’s CEO, was that data for training AI models is “limited”.
It might feel extremely weird to claim the massive amount of data all the models have access to is actually limited. But if you think about it, it kind of makes sense. For example, assume you train a model with StackOverflow data. If LLM models eventually replace StackOverflow, where would the new data come from? Now extrapolating farther, if LLM models eventually replace the knowledge found in the internet, where will new knowledge come from?
In this brand new and long due episode of Biweekly Engineering, we will not discuss about the data issue. Let’s shift our focus to one of the most-discussed topic on what’s next and ongoing for AI — agentic systems.

The majestic Rest and Be Thankful Viewpoint in upper Scotland, UK
Building Effective AI Agent — A Guide from Anthropic
Anthropic draws an explicit distinction between agents and workflows:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
While both systems can be deemed as agentic systems, think of workflows as deterministic due to strict applicability of instructions, whereas agents are more non-deterministic and dynamic, capable of taking decisions based on their interactions with the environment.
Should you build agentic systems? Yes, only if you need it. Just like you shouldn’t use LLM when a problem can be solved with something much simpler, you shouldn’t use agentic systems when having a simple LLM-based approach is enough. The reason is pretty simple — such systems will only add complexity to your architecture.
This piece of advice is actually universal in software engineering — always go for simple and stupid solution if it works. Sophisticated systems should be built if and only if they are required.
A note on non-determinism
LLMs are inherently non-deterministic. There is no guarantee you will get the same output every single time you ask the same question to an LLM. And this is in fact not a bug, but a feature.
But non-determinism is not always easy in software systems. We prefer determinism. It is much easier to handle infrastructure, errors, tests, responses from other systems—basically everything when your systems are deterministic.
Is the non-determinism bad? Not always. There are many use-cases where the non-determinism behaviour gives a much better experience to end users. But at the same time, it makes building systems with LLMs more difficult.
So to reiterate what Anthropic suggested—use agentic systems (workflows and agents) only when you absolutely need them.
When to use frameworks
To build LLM-based systems, there are already quite a few frameworks, and the most popular one is LangChain. LangChain comes with LangGraph, a framework to build agentic systems.
Anthropic suggests to avoid using frameworks in the early stage of development process if the underlying mechanism is not well-understood. The main issue with agentic frameworks, like every other frameworks in software engineering, is that they hide a lot of the details behind layers and layers of abstraction. This is disadvantageous if you want to understand what's going on under the hood, or you need to debug.
So start simple, build on top of it, and go for more complicated approaches based on needs.
Patterns of agentic systems
The basic building block for an agentic system is an LLM enhanced with a few capabilities: retrieval, tools, and memory.
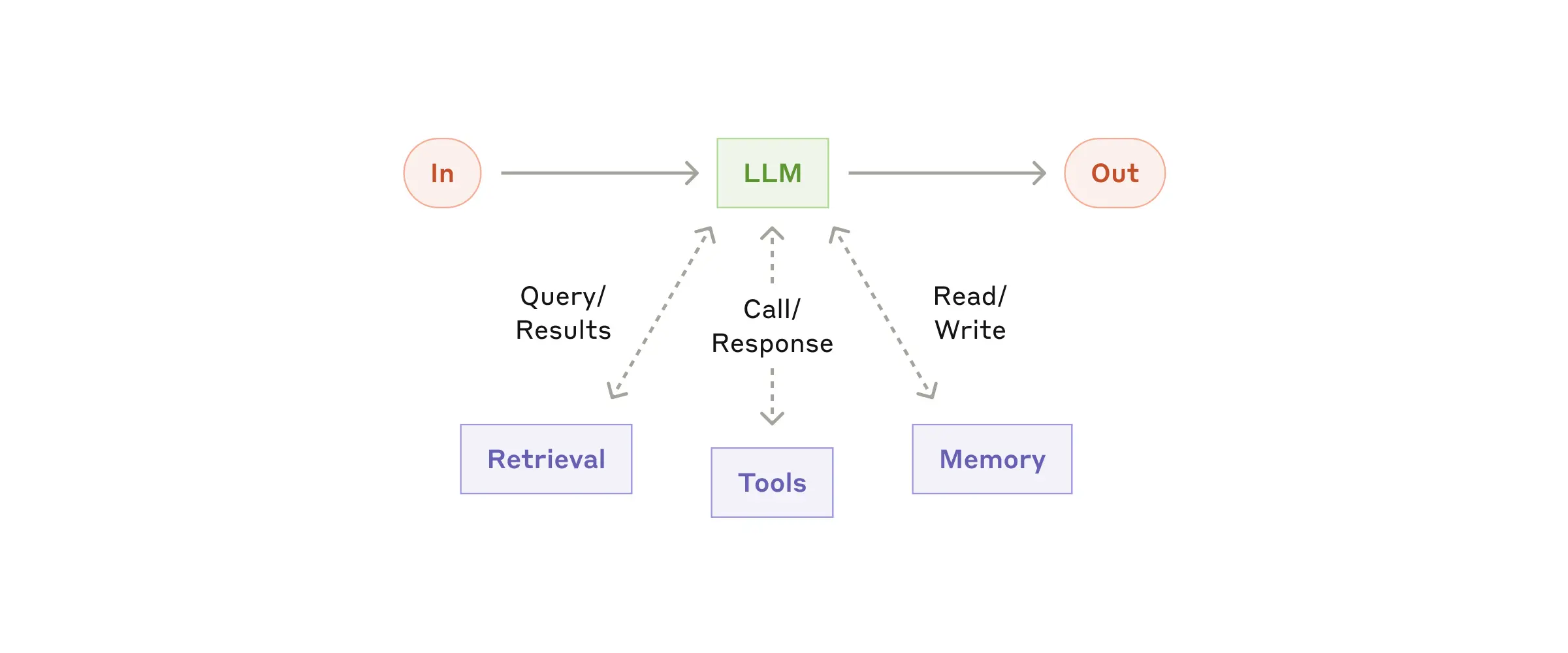
From Anthropic
As the diagram shows, in a basic setting, an LLM upon receiving a request, can query or search for some data (retrieval), call external/internal entities to further process the response (tools), and store data if needed (memory).
Based on this basic building block, Anthropic outlines couple of patterns:
Prompt chaining: Useful when a task is a sequence of steps where each output from one LLM call is fed into the next one.
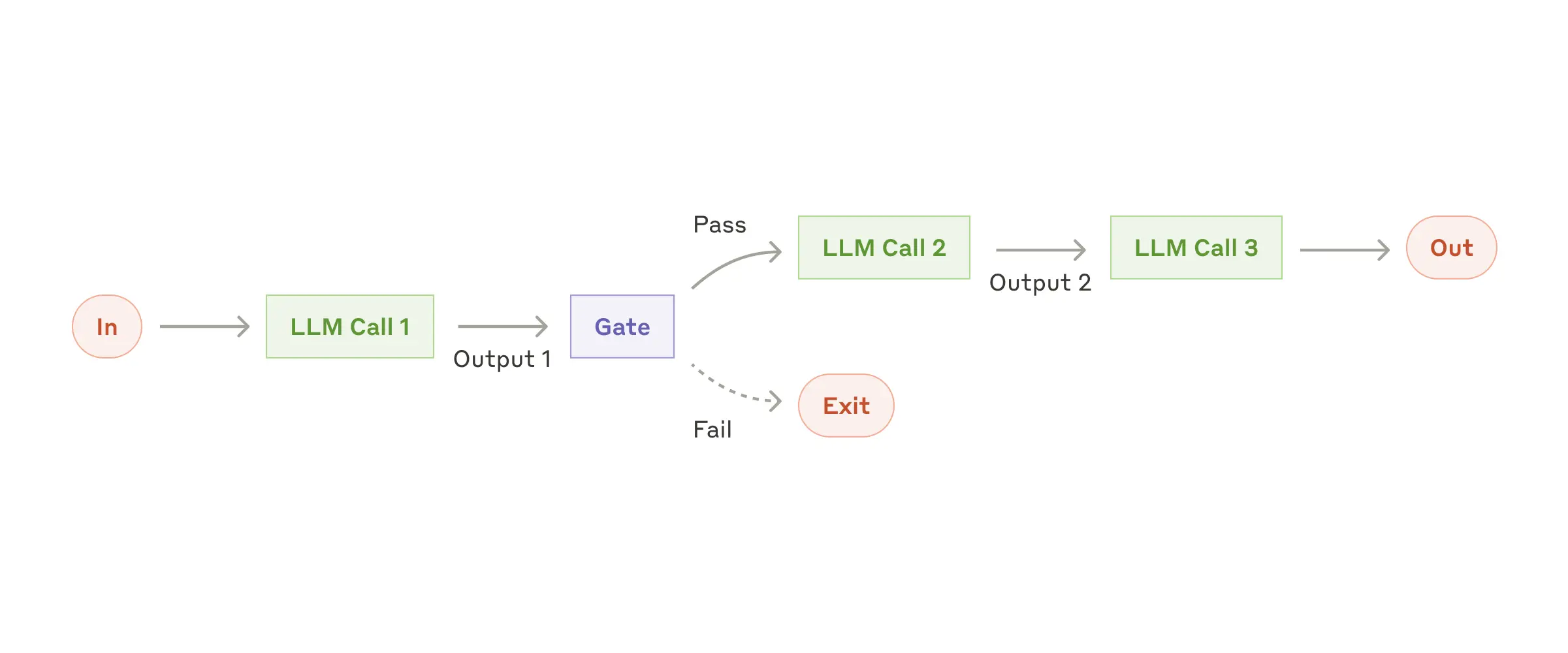
Prompt chaining
Routing: For a variety of tasks, different LLMs can do different tasks based on their specialities, and a router decides which LLM to call for which case. For example, smaller models can be suitable for easy/common knowledge-based questions but bigger models can be suitable for harder tasks like reasoning.
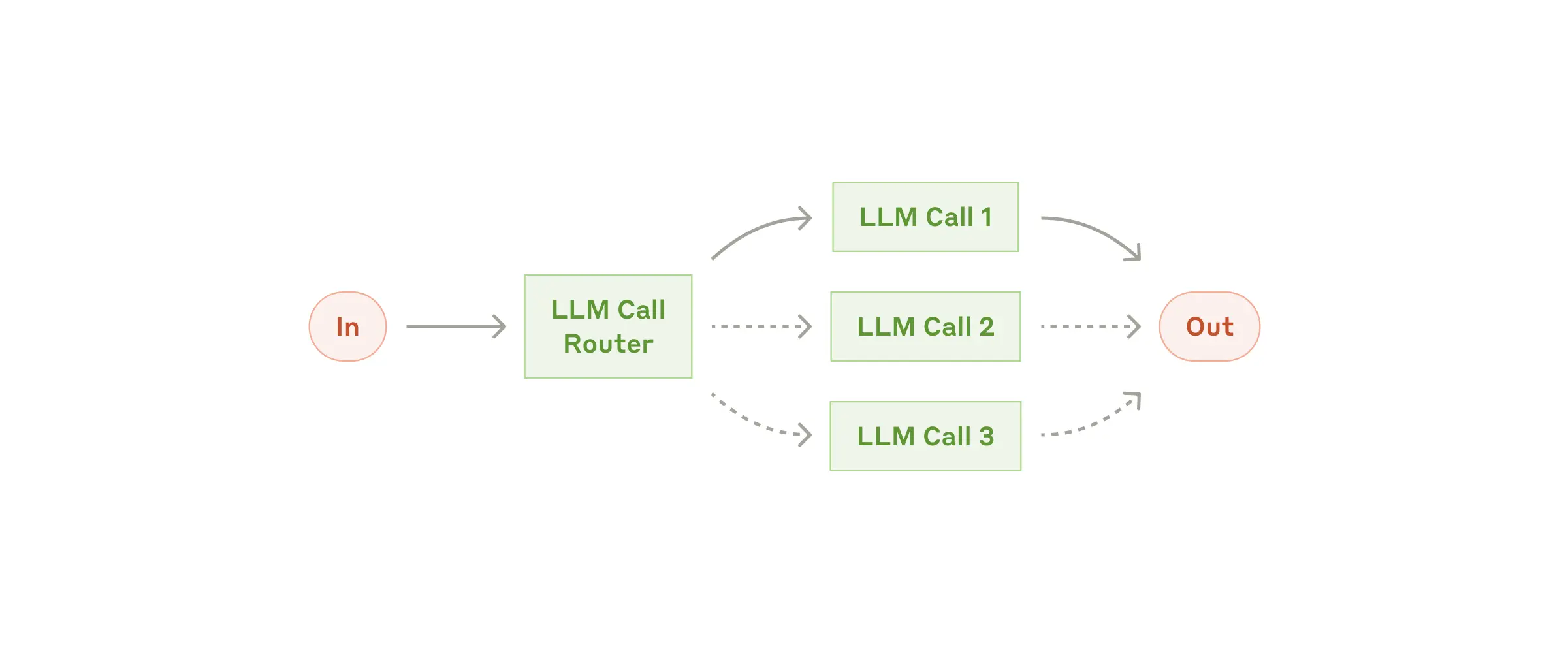
Routing
Parallelization: A task can be broken down into parallelizable subtasks and multiple LLMs can be invoked at the same time to execute it. An aggregator is used to aggregate/decide the final output.
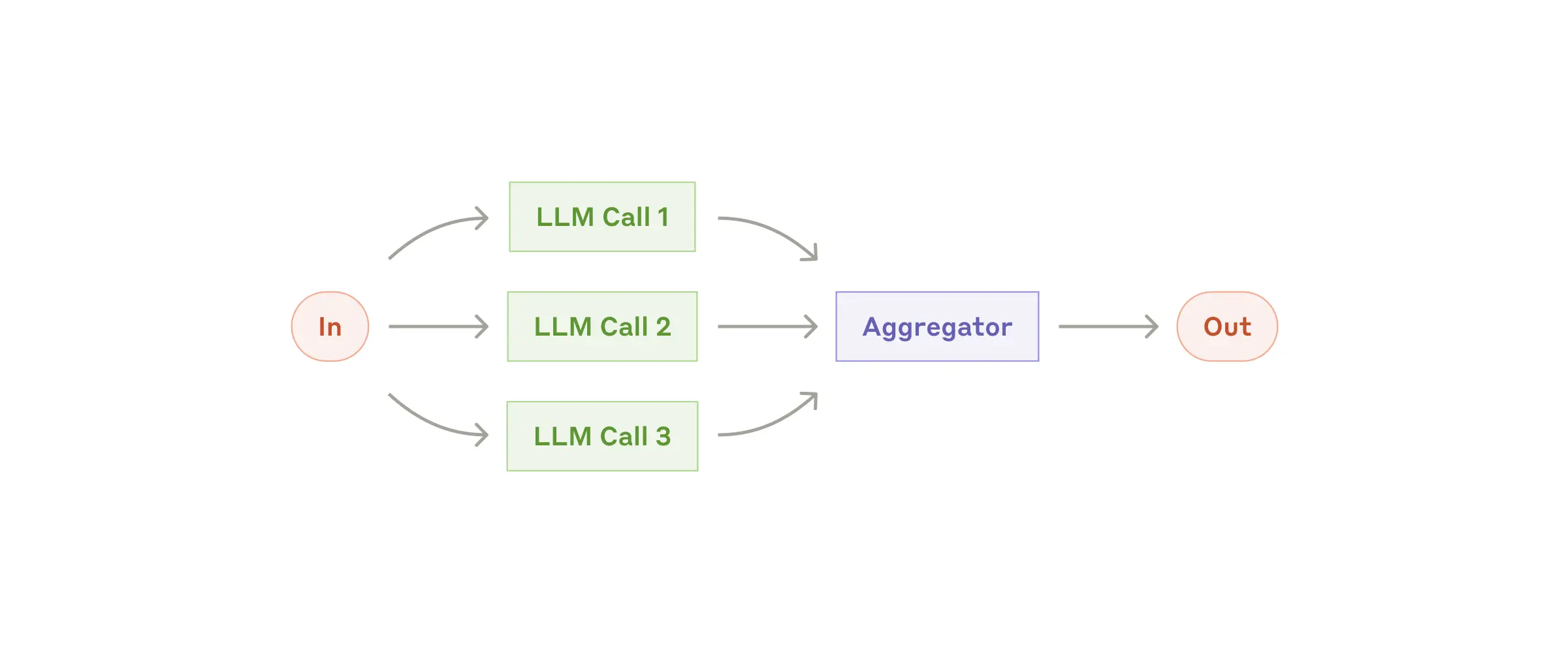
Parallelization
Orchestrator-workers: For more unpredictable/non-deterministic tasks, an orchestrator LLM is used to figure out what the subtasks should be and dispatches the subtasks to different LLMs. The difference with parallelization is that subtasks in orchestrator-workers pattern are not predefined.
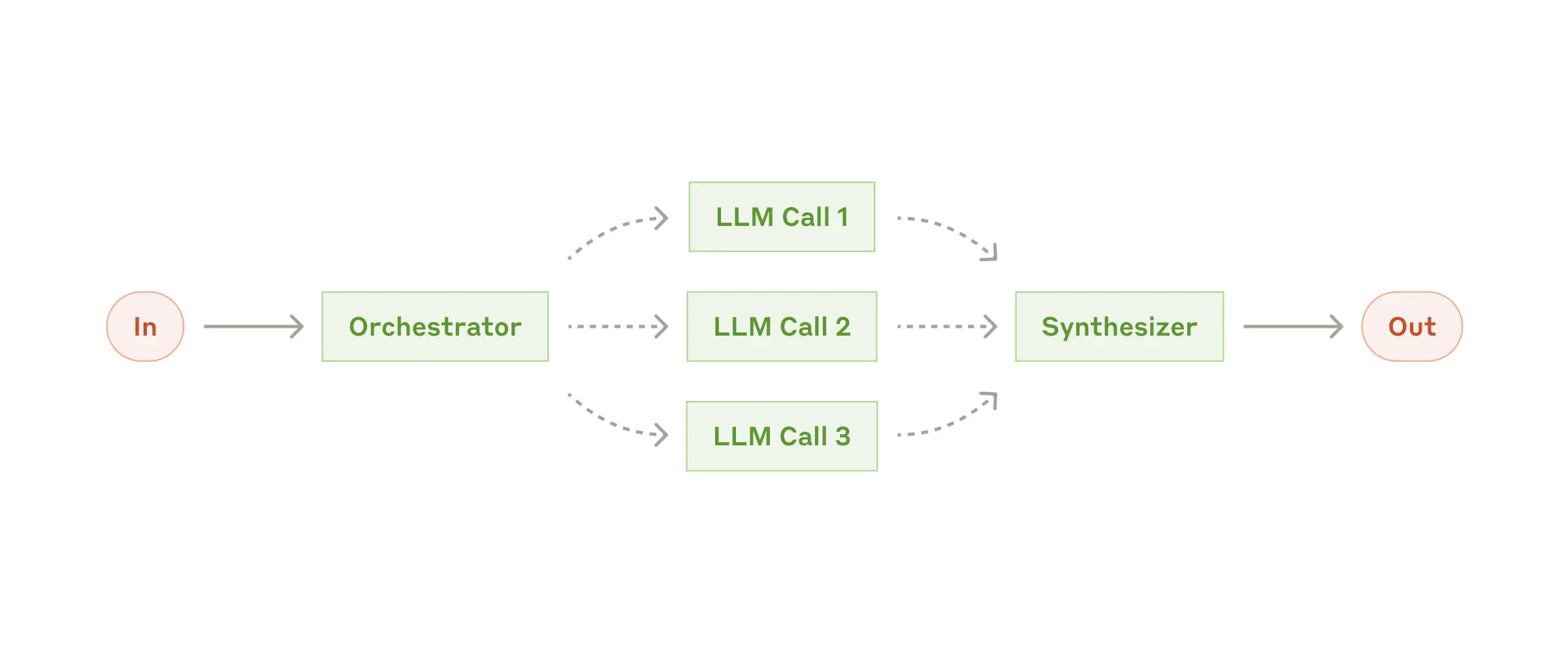
Orchestrator-worker
Evaluator-optimizer: In case we have clear evaluation criteria, there can be one LLM that generates output and another one accepts or rejects with feedback. This feedback loop continues until the evaluator accepts the output from generator.
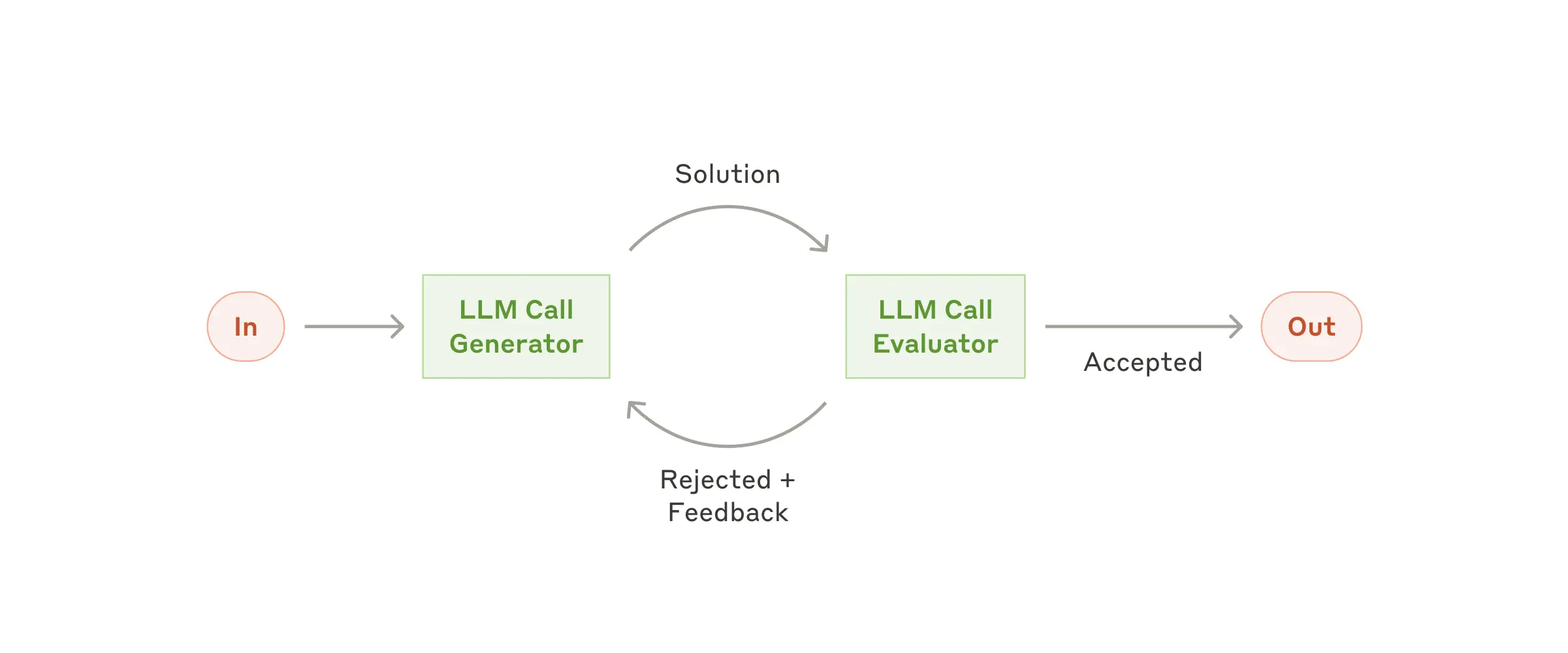
Evaluator-optimizer
But when to use agents?
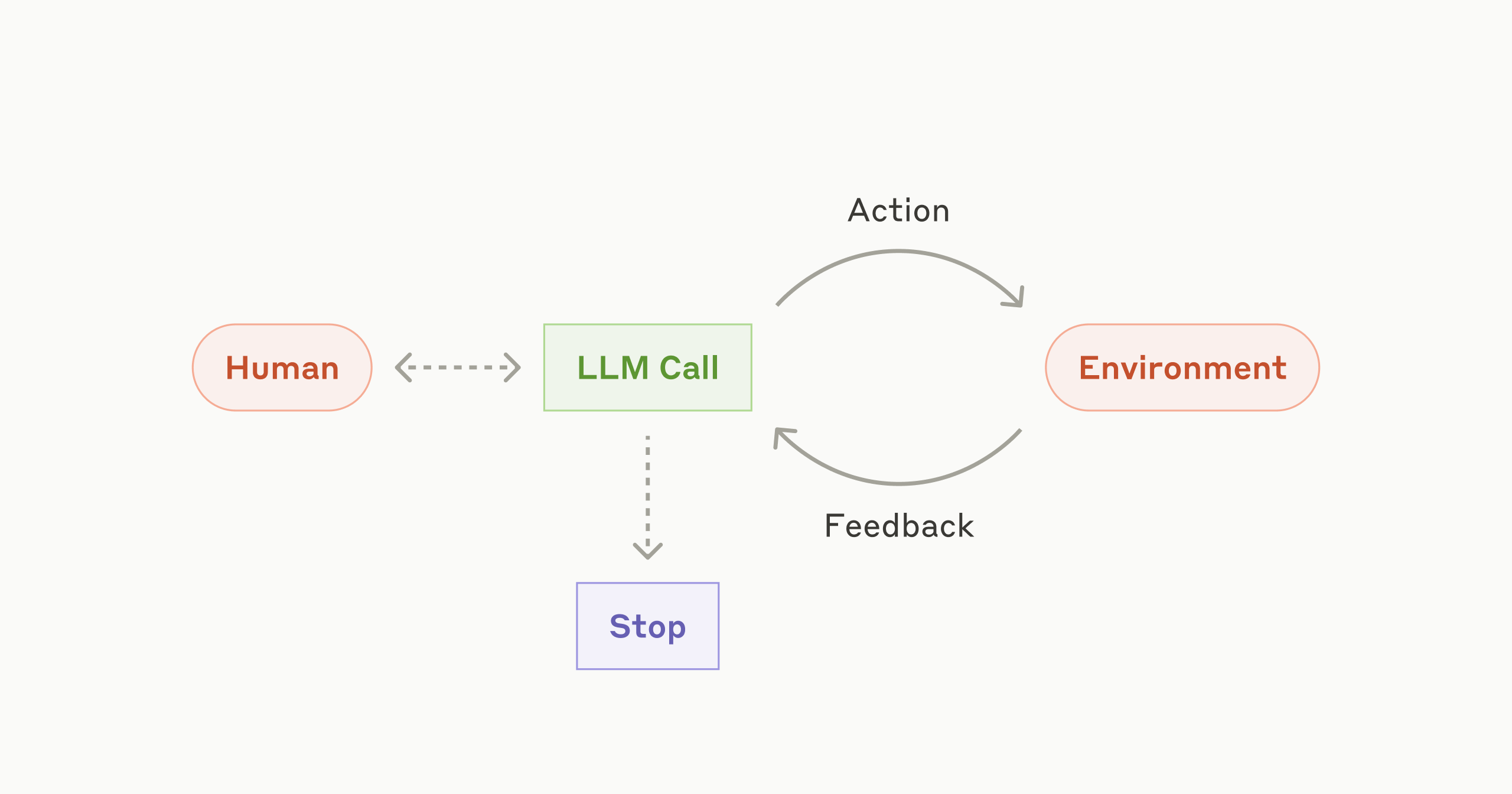
The above patterns of agentic systems are basically workflows where we can decide strictly what steps to take. But in case of agents, we do not know what steps might be needed. It is upto the LLM to decide and act. It should be autonomous.
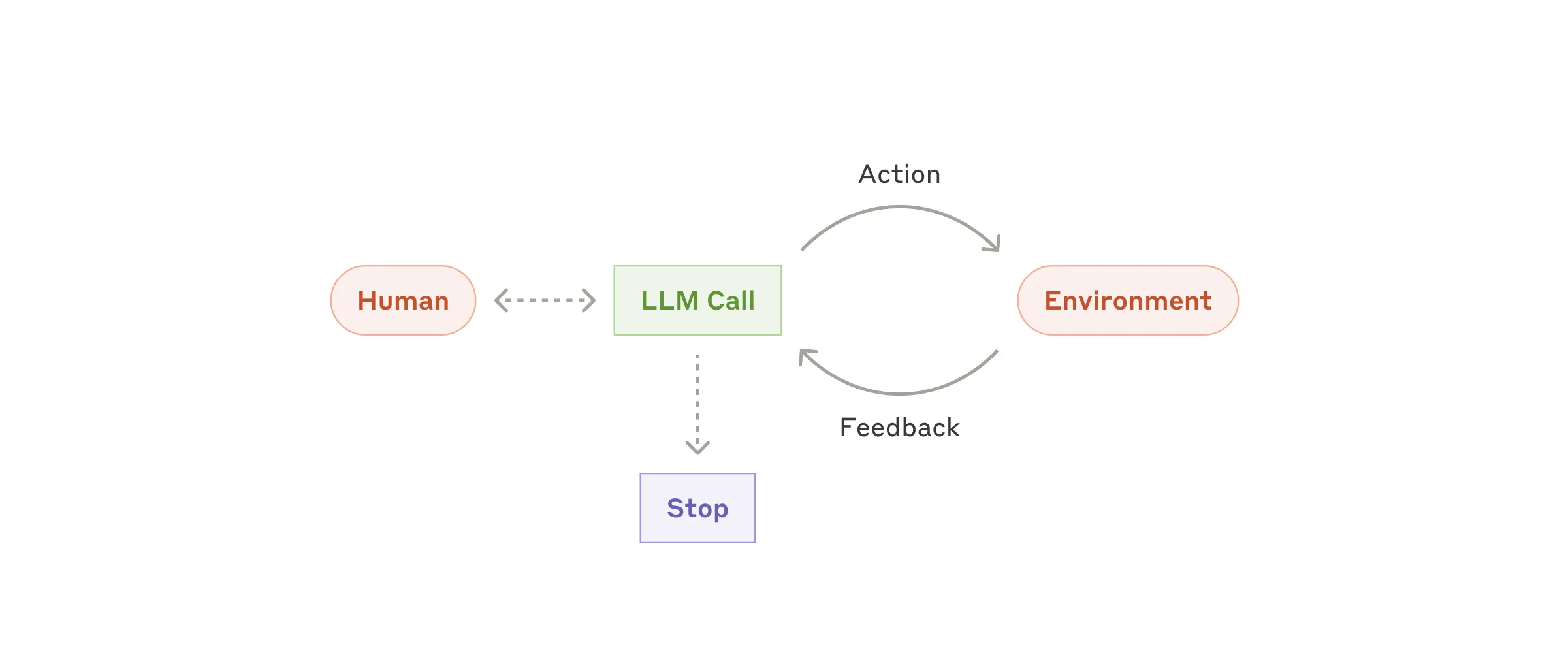
Agent in action
Agents are useful for open-ended problems where we don’t know a fixed path that an LLM can take. Here, we rely on LLM’s own evaluation based on its interaction with the environment and available tools.
One use-case where agents could be incredibly useful is coding. Agents can read the code, decide what to do, run it, take the feedback, and reiterate. Given that different codebases have different criteria, it’s difficult to define a fixed path for an agent to take.
And that’s a wrap for today. The article discusses the patterns in great details with appendixes on agents and tools. A highly recommended piece for anyone interested in AI-driven architecture development.
See you (hopefully) soon in the next one! 🐋
Reply