- Biweekly Engineering
- Posts
- Building A Real-Time Data Infrastructure: The Uber Way | Biweekly Engineering - Episode 30
Building A Real-Time Data Infrastructure: The Uber Way | Biweekly Engineering - Episode 30
How Uber built an end-to-end real-time data infrastructure using open-source technologies
Biweekly Engineering
May 14, 2024
Hiya! Long time no see!
After a break, your favourite newsletter Biweekly Engineering is back! It feels great to bring in a brand new episode for my readers. Hope y’all have been doing great!
Today, we will discuss Uber’s real-time data platform that handles mind-boggling scale and solves numerous business use-cases. Let us all make a cup of coffee, sit back on our favourite couch 🛋️ and enjoy the read! Without of course, falling asleep! 😴

University of Edinburgh, Scotland
The Real-Time Data Infra at Uber

How did Uber build its comprehensive big data platform that handles petabytes of data every single day?
Context
The following diagram gives us a pretty good context on what a data platform is. Notice the sources of data on left side where data is originating from a variety of sources like mobile app events, telemetry, logs, etc. In the middle, there is the data infra that ingests, processes, and materialises insights from the massive ocean of raw data. Finally, the right side shows many different consumers of the generated data which essentially run a successful business.

Diagram from the article
The biggest challenge of such a real-time platform is the scale. How to scale data storage and data processing while satisfying hundreds of use-cases from pretty diverse group of users and business entities?
All the building blocks
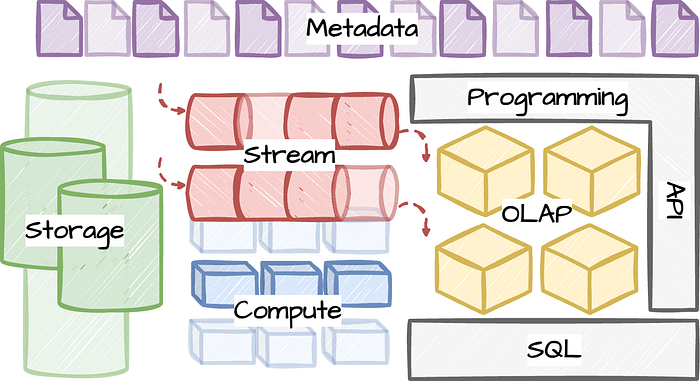
Diagram from the article
The well-crafted diagram above denotes the building blocks of the data infra at a high level. Let’s briefly discuss.
Storage
On the left, we have storage layer. This layer provides storage support for all other layers.
Stream
The streaming layer, as you expect, provides other layers streaming support through pub-sub interfaces.
Compute
This layer takes care of computational workload on top of storage and streaming layer.
OLAP
Short for Online Analytical Processing, the OLAP layer provides storage support which is optimized for running analytical queries on the derived data by the compute layer.
SQL, API, Metadata
SQL layer provides SQL capabilities for querying data. API layer provides programmatic interface for different systems to consume the data. And metadata layer provides all kind of metadata support for all the different layers.
Open-source systems to power up the building blocks
Uber massively relies on open-source softwares and systems. This has been beneficial for the open-source community as Uber actively contributes to such projects while using them production.
To build this comprehensive real-time data infrastructure, Uber extensively leveraged open-source technologies and in the process of doing so, they enriched these technologies.
Apache Kafka: streaming and storing events
Apache Kafka, the de-facto solution for even streaming, is at the centerstage of the real-time data infra at Uber. Originally built at LinkedIn, Kafka takes care of streaming all types of data throughout the infra from source to sink.
Uber has one of the largest Kafka deployments in the world.
While building such a large Kafka fleet, Uber faced challenges at high scale. This is why they had to implement various solutions like cluster federation, dead-letter queue, consumer proxy, and cross-cluster replication. The article discusses the problems behind these solutions and how Uber managed to build them.
Apache Flink: processing events
To build a real-time data infra, you need a real-time (or near real-time) stream processor. Uber users Apache Flink, another widely used and probably the most popular stream processing platform in the industry.
Uber developed FlinkSQL that transforms SQL-style queries to Flink jobs. Along the way, the team had to solve resource estimation, auto scaling, failure recovery and monitoring problems.
Apache Pinot: OLAP layer
Now that Apache Kafka streams the data and Apache Flink processes it, who is going to serve the data for consumers to consume? Enter Apache Pinot.
Another system developed in LinkedIn, Pinot is a specialised database solution that is optimised for analytical queries. Analytical queries provide insights to data analysts, data scientists, product managers - pretty much a lot of teams in a company to understand the business and the impact of their work. Not only that, in some use-cases, analytical queries can serve customers. For example, serving daily reports to advertisers in an advertising company.
How far Apache Pinot can go to optimize analytical queries? Guess what, the database has an exclusive indexing strategy called Start-Tree indexing! Check the reference section for more details.
HDFS & Presto
One of the most popular file storage system, HDFS is in the core of Uber’s data platform. It provides archival storage support for all data, along with interim, backup, and long-term storage support for systems like Flink, Pinot, and Kafka.
On the other hand, Presto, a popular distributed query-engine, powers up the query layer of the system to write and execute analytical queries on top of HDFS, RDBM, NoSQL systems.
Uber’s use-cases
Uber has developed solutions for critical use-cases on top of the infra discussed in the article. For example:
Surge pricing to bump up fares when there is high demand
Real-time dashboards for restaurant managers to visualise performance of their restaurants
Automation for the work of operational teams
References
This marks the end of today’s episode. I really enjoyed reading the article, and I highly recommend my readers to do the same! I am sure you will learn something new.
I will leave you with that for today. See you in the next one. Till then 👋
Reply