- Biweekly Engineering
- Posts
- Critical Traffic Migration at Netflix - Biweekly Engineering - Episode 17
Critical Traffic Migration at Netflix - Biweekly Engineering - Episode 17
How Netflix migrates critical traffic at high scale - Scalable real-time event processing at DoorDash
Biweekly Engineering
July 17, 2023
Hey hey awesome subscribers of Biweekly Engineering! Welcome back to the 17th episode of your beloved newsletter. Today, I am back yet again with intriguing articles from Netflix and DoorDash.
Can’t wait to read? Let’s go!

Rotating head of Franz Kafka in Prague, Czechia
How Netflix Migrates Critical Traffic at Scale
Part 1 — How Replay Traffic is Leveraged
Netflix is a HUGE system. Given it’s tremendously large business worldwide, it is crucial that the system is always operational, and never goes down. But how to do different sorts of migration without impacting the business and keeping the systems online? As you can imagine, at the scale of Netflix, migrating without downtime can be a challenging feat. Today, we get a peak into the strategies Netflix has for large scale migration with zero downtime.
This is a two-parts series where the first part discusses how Netflix carries out testing for the migration. Basically, when you have a new system you want to migrate to, you need to make sure the system works as expected, gives correct outputs, and capable of handling the load it is required to.
The strategy discussed in the first part is named replay traffic. To quote from the post-
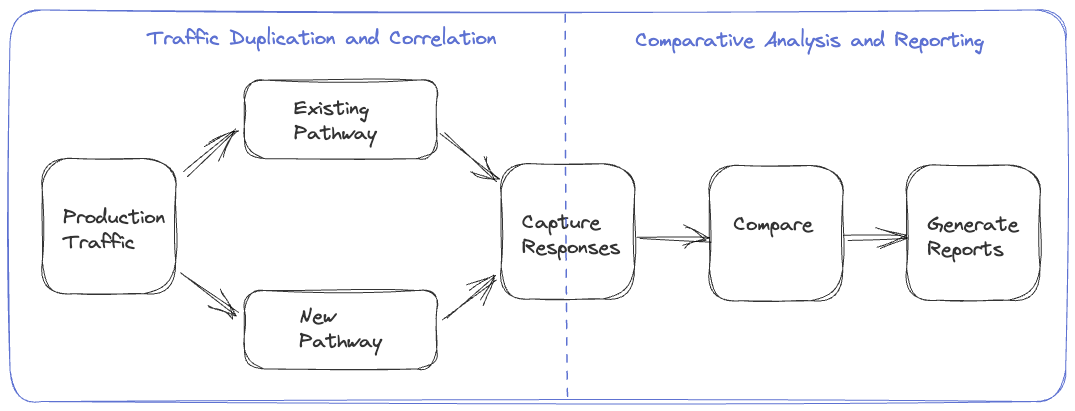
Replay traffic refers to production traffic that is cloned and forked over to a different path in the service call graph, allowing us to exercise new/updated systems in a manner that simulates actual production conditions.
To explain, in replay traffic, at some point in the call graph, a request is sent to two different paths instead of one. The first one is the existing one that is in use right now to serve users, and the other one is the new path the system will adopt after migration. Response from the first path is sent back to user, and response from the second path is used to analyse and test the correctness.
How is the response analysed and tested for correctness? As you can expect, response from new and existing paths are captured and compared. Then a comparative analysis is carried out to test the correctness and a report is generated. Based on the complexity of migration, the comparative analysis could possibly involve anything between a simple equality check to complex statistical analysis.
There are three different approaches to generate and handle replay traffic—in user devices, in the existing production backend servers, or entirely in new services. The article discusses these different approaches in details, and their advantages and downsides.
Part 2 — Carefully Controlled Migration Process
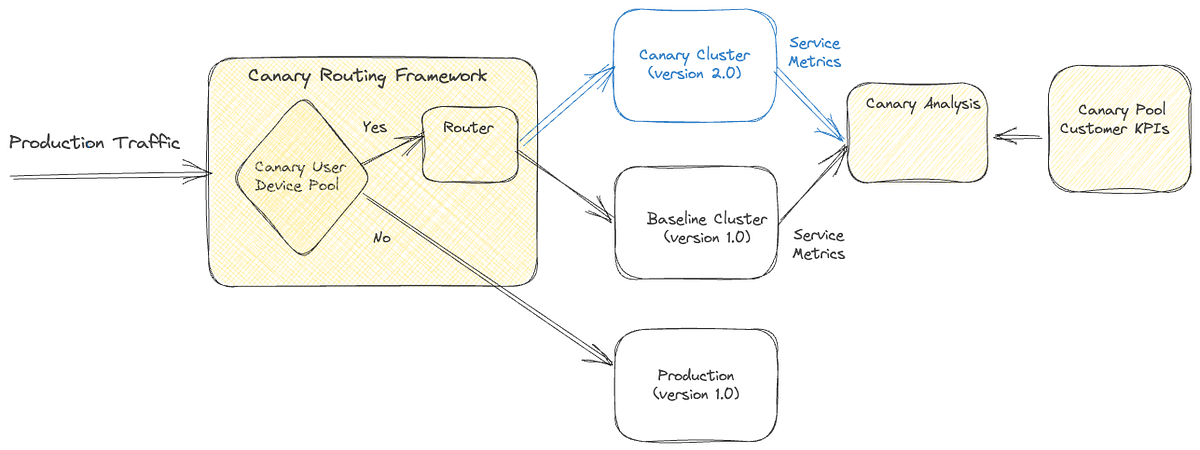
In the second part of the series, the authors discuss how migration process is conducted to rollout new changes and systems to production traffic. While the first part shows how validation is done to ensure correctness and effectiveness of the new systems, the second part shows how to start using the systems in a controlled manner, without effecting the end users.
The article discusses different strategies like sticky canaries, A/B testing, and dialling traffic. We also get an idea how persistent storages are migrated. Fortunately, the ideas are also more or less applicable in many different use-cases in other systems, not only for Netflix.
Scalable Real-Time Event Processing at DoorDash

What does it take to build a real-time event processing system at high scale? DoorDash has an answer for this question. It requires Apache Kafka and Apache Flink.
The article discusses how a generic event-processing system was built in DoorDash. It starts with how the legacy system used to work, what its bottlenecks were, and why they felt the need to improve the system. In summary, the team wanted to meet the following needs-
Being able to ingest data from a variety of sources and persist the output in a variety of sinks
Making access to data streams simple for the product teams
Enforcing and evolving data schema end-to-end
Operating with fault tolerance and high scale
Looking at the needs, the team was confident that Apache Kafka would be the best solution for data streaming whereas Apache Flink would be suitable for stream processing. Both of these are actually the leading technologies in their respective domains.
I particularly liked the article a lot due to its detailed nature. The authors discussed how the team optimised and developed event producing, Kafka producers, Apache Flink jobs, schema validation, data warehouse integration, etc.
And that is enough for today! Make sure to go through the articles shared and make it a habit with the help of Biweekly Engineering! :)
Do you find the newsletter useful? If so, share it with your friends and colleagues: https://biweekly-engineering.beehiiv.com/subscribe
Reply