- Biweekly Engineering
- Posts
- Design Patterns in Distributed Systems | Biweekly Engineering - Episode 25
Design Patterns in Distributed Systems | Biweekly Engineering - Episode 25
A high-level overview of different design patterns in the distributed systems world
Biweekly Engineering
January 09, 2024
Welcome dear readers to the 1st episode of Biweekly Engineering in 2024! 🎉 I hope ya’ll have been doing great!
In this new year, let us all have a resolution. Repeat after me: “we will always read all the articles shared in Biweekly Engineering.”
Now that my carefully crafted new year’s advice for my readers has been successfully conveyed, let’s start today’s episode.
In this episode, I have only one article to share because it’s a big one. I found this great piece from freeCodeCamp that gives us a high-level overview of various design patterns in distributed systems.
I am particularly excited to share this post as the field of distributed systems is one of my area of interests. Some of you know that I have a course on Educative on introduction to distributed systems:
Okay self-advertisement is also done. Now let’s jump right in!

The majestic Kotor Bay in Montenegro
Distributed Systems Design Patterns - A High-Level Walkthrough

The articles starts with prerequisite knowledge of distributed systems. If you are a regular reader of this newsletter, I can safely assume you have the prerequisite knowledge already.
What is a distributed system?
Though the goal of the post is to discuss various distributed systems patterns on a high-level, we also get a definition:
A distributed system is a computing environment in which various components are spread across multiple computers (or other computing devices) on a network.
While the above is an acceptable definition, I would also like to provide a more text-bookish definition:
A distributed system is a collection of autonomous computing elements that appears to its users as a single coherent system.
If you are curious to learn more about the definition, feel free to check the lesson from my course that discusses it in detail. This lesson is not behind a paywall.
Does every system have to be distributed?
Unsurprisingly, the answer is a big-fat NO. We need to acknowledge that distributed systems are hard to build and maintain. A system should be designed in a distributed manner if and only if it is required.
As the article points out, a distributed system comes with its fair share of complex challenges. You have to make a conscious decision before taking this journey.
Design Patterns of Distributed Systems
Let’s dive into the juicy part of today’s episode. I will briefly discuss a few of them to give you a kickstart. Don’t forget to read through the article to explore more!
Command and Query Responsibility Segregation (CQRS)
The first pattern we have is CQRS.
I have personally worked on systems built using this pattern. It is very useful in high-scale where separating out read and write path makes sense. But as you can expect, this pattern is complex to build and maintain.
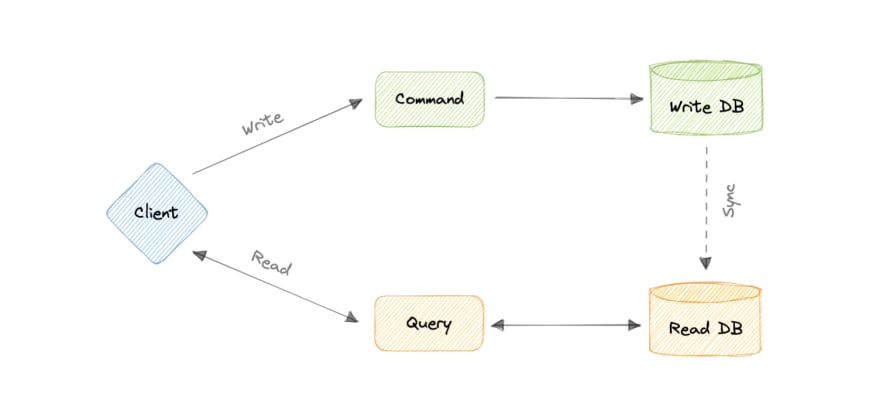
As the diagram depicts, reads and writes take separate paths through separate systems. Data is synced between the two databases so that reads can be served with updated data.
The major advantage of CQRS is scalability. Writes and reads are from different databases which allow both of the databases to be more optimised and scaled accordingly.
2-Phase Commit
2PC is a pattern used in distributed transactions. Briefly, the idea is to have a coordinator that commits data in two phases - prepare and commit. The prepare asks each of the participating system to prepare the data and the commit phase commits the data.
To achieve transaction guarantee, participating systems in 2PC have to acquire locks during which no writes can proceed. This is why 2PC is also known as a blocking or anti-availability protocol.
Saga
Saga is another pattern used in distributed transactions. Here, locks are not acquired. There are two approaches in Saga:
Orchestration - An orchestrator service orchestrates the transaction by commanding other services to update or reconcile their data based on the state of the transaction.
Choreography - In this approach of Saga, everything happens through events. Participating systems put events in a message broker and every system reacts to events. It also means reconciliation happens through publishing and processing events.
Distributed transaction is one of the most complicated topics in the distributed systems field. The article only scratches the surface!
Sidecar
A sidecar is a helper container in a container group (for instance, a pod in Kubernetes) that sits alongside an application container. This pattern is ubiquitous in microservices world, specially with the birth of Kubernetes and Kubernetes-like container orchestration platforms.
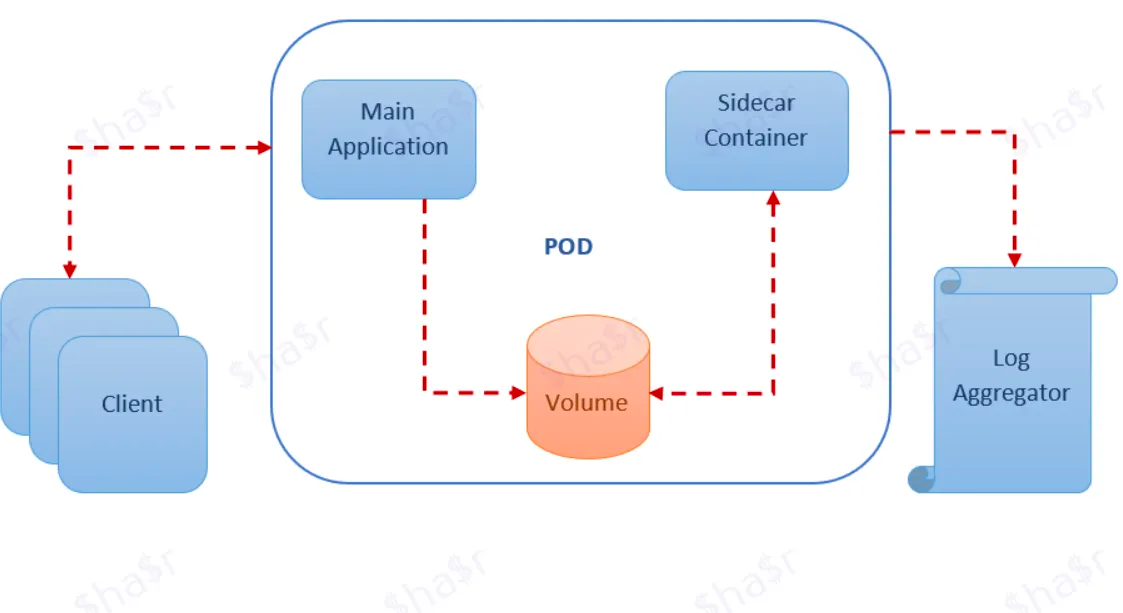
In the above diagram, the Kubernetes pod contains two containers: a container that has the main application deployed and a sidecar container.
The responsibility of the sidecar container is to periodically read the disk and publish the logs to a log-aggregator system.
Service Registry
Another pattern used in microservices - in service registry, every microservice has to register itself (name, IP, port, anything else that’s required) to a registry so that it is discoverable. Why though?
The reason is pretty obvious - in distributed systems, any service can go down any time and a new one will be created. If a service has a new instance that can serve requests, how would other services know the address of the new instance?
This is where service registry comes into play. Every instance has to connect to service registry upon starting and register its address. So when a client needs to connect to a service, it knows where to look for.
And this is where I end today’s episode. I intentionally left out many of the patterns so that you can take your time to check the original article. It has an overview of many patterns. If a particular design pattern makes you more curious, dive deep to understand it more! 🙂
Adios for today! 👋
Reply