- Biweekly Engineering
- Posts
- Duplicate Stories in Medium Feed - Biweekly Engineering - [Special] Episode 20
Duplicate Stories in Medium Feed - Biweekly Engineering - [Special] Episode 20
How Medium resolved an issue of duplicated stories on the homepage feed
Biweekly Engineering
September 06, 2023
Good day dear subscribers! Welcome back to the 20th episode of Biweekly Engineering - your source of curated software engineering blog posts from the internet!
In this special episode, we're going to do something a little different. Instead of our usual format of discussing multiple blog posts, we're going to be taking a deep dive into a single postmortem blog post from Medium Engineering.
Let’s run!

The age-old tram line in the Hague, Netherlands
How Medium fixed duplicate stories in the For You feed
What is the For You feed?
When you log into your Medium account, there is a personalised homepage that shows a list of suggested stories to read. This is called the For You feed at Medium.
What went wrong?
Medium started to receive reports of stories appearing multiple times in the feeds for its users. The impact was not so small:
Instrumentation showed that there were around 4K occurrences per day of duplicate stories on iOS and around 3K occurrences per day on Android.
And the same issue was also reported for the web app.
How the For You feed works
We can summarise the flow as below-
Requests from iOS, Android, and web go to a GraphQL layer.
GraphQL layer resolves the requests to a service called “rex” which is responsible for generating the feed for the users and serving it. rex computes the feed with the help of multiple downstream services.
Upon generating a feed for a user, rex caches the data in a Redis cluster.
The API is paginated.
When a feed request for a user is sent to rex, and there is no feed available in the Redis cache, a new feed is generated for the user, and stored in the cache against the key
$userId:HOMEPAGE. So feeds are generated lazily (when required) instead of eagerly (on a schedule for all the users).Each generated feed has a TTL of 30 minutes.
Root cause analysis
Background goroutines to store the feeds in Redis
The rex service is implemented in Go. When a new feed generated, code like the following runs:
f := FetchFromRedis(ctx, userID)
if !f {
f = GenerateFeed(userID)
go StoreInRedis(ctx, f)
}
return extractPage(f, paging) Note that the StoreInRedis function is called using a goroutine, with the original request context (ctx) being passed to the function.
A defining feature of the request context in Go is that it gets cancelled as soon as the request is finished. So when the request has been served, the context is cancelled, which means any unfinished work that has the same context will also be cancelled.
This is what exactly happening here: writing the feed to Redis can non-deterministically fail at any point because the request is already finished and the request context is cancelled!
But how does this problem create duplicate requests? It is well-summarised in the following diagram:

In the first request for a feed, there is no feed available in the cache for the particular user. A new feed is generated, say it’s called feed instance A.
StoreInRedisfunction is concurrently called in a goroutine passing the request contextctx.First page of the feed is sent back to the client from the generated result.
In the meantime, since the request finishes,
StoreInRedisfails somewhere in the middle before successfully writing the feed on Redis. So, there is no feed A in the cache right now.After retrieving the first page, the client now requests for the second page of the feed. Note that, there is no feed A in the cache! So a new feed instance B is generated.
Perhaps this time, the
StoreInRedisfunction manages to finish before the request is completed.The second page from the feed instance B is now sent back to the client.
In the two subsequent requests, the client received the first page of feed A and second page of feed B! These two feeds are generated separately, and two of them can have one or more same stories. This behaviour is actually expected because the feeds generated by rex with the help of downstream services, and there is no guarantee that same story cannot appear in two different generation.
Users returning to the same feed after being idle for more than 30 minutes
Interestingly, that’s not it. There is another scenario where duplicate stories on the same feed might appear:

A user comes opens Medium. There is no feed in the cache, so feed A is generated, and stored in Redis.
First page of the feed is returned to the client app.
The user remains idle for more than 30 minutes and comes back. Note that 30 minutes is the TTL for a feed in the cache. Since the user is now scrolling further, second page request is sent to rex.
At this point, the feed generated earlier is evicted! So a new feed is generated and its second page is sent back to the client.
As you can see, this is similar to the previous situation where a client receives first page from feed A and second page from feed B! Hence, a user can again view the same story twice on the Medium app.
Remedies for the issue
The remedies can be summarised as below:
For the first scenario (passing request context in
StoreInRedisgoroutine), the solution was to create a newBackgroundcontext and pass it to the goroutine. As a result, even if the requests context is cancelled, the goroutine continues to execute and stores the feed in Redis.For the second scenario where a user is idle for more than the TTL in Redis, the solution was to update the key for persisting the feeds. Instead of using
$userId:HOMEPAGEas the key, it was updated to$userId:HOMEPAGE:$feedId. When a client requests for a page from the feed, thefeedIdis also specified in the requests along with the cursor for the page. Apart from that, the latest feed is also attached to the key$userId:HOMEPAGE:currentto distinguish the current feed from other feeds for a user.
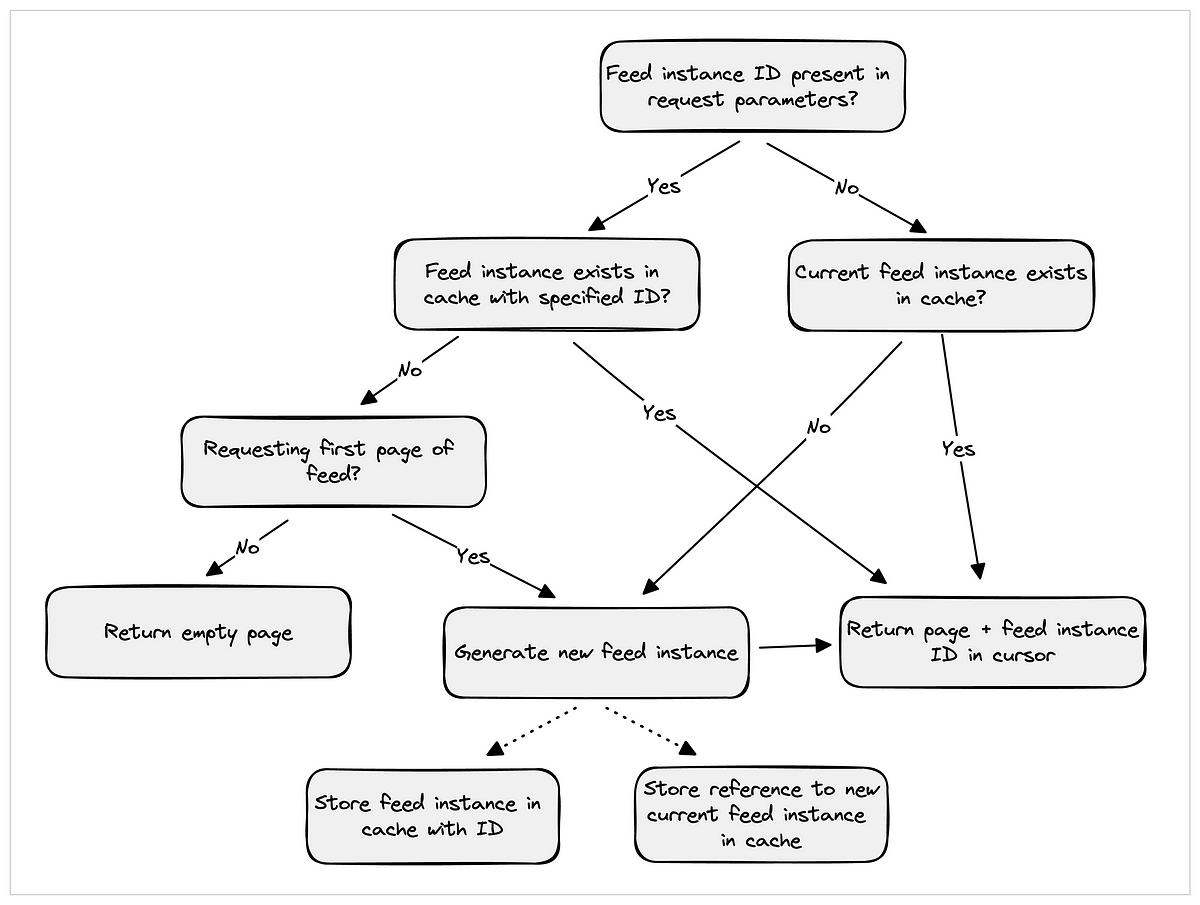
The following diagram now depicts the flow:

How does the above ensure that no story appears twice in a feed?
If a client sends a request with a feedId and it doesn’t exist in the cache, then a new feed is generated only if the client is requesting for the first page of the feed. Otherwise, an empty page is returned. This way, a client will stop receiving one page from one feed instance and the next one from a different feed instance.
The last piece of the puzzle was TTL. TTL for each different feed for a user was set to 1 hour. This ensured that a user can be idle on the Medium app up to an hour and still can continue to scroll through. On the other hand, TTL for the current feed (key $userId:HOMEPAGE:current was set to 10 minutes to make sure there was enough freshness of the feed for a user.
The outcome of the effort
Graphs showcase the outcome:

iOS duplicate stories occurrences per day

Android duplicate stories occurrences per day
As you can see, the issue got resolved after the updates were rolled out completely. :)
Interesting, isn’t it? In software engineering, tracing such issues and solving them is a common phenomenon. We humans create the bugs, and we humans eventually solve them.
That would be all for today. Hope you enjoyed this episode, and looking forward to the next one. See you very soon!
Reply