- Biweekly Engineering
- Posts
- Event Compaction in Husky: Datadog's In-House Event Storage | Biweekly Engineering - Episode 40
Event Compaction in Husky: Datadog's In-House Event Storage | Biweekly Engineering - Episode 40
Achieving high-scale in Husky—Datadog's in-house event storage system
Biweekly Engineering
June 28, 2025
Husky is the event storage system in Datadog. Made in-house, the system ensures scalability while keeping the performance intact. The core mechanism to achieve this is compaction.
But what is compaction? And how does Husky do it to ensure performance at scale?
Today, we will learn more!

Roaming around the Giza Plateau, Egypt
A Quick Primer on Compaction
What is Compaction?
Compaction in storage systems is the process of reorganizing and rewriting data to improve space efficiency, read performance, and maintain consistency over time. It typically involves three stages:
Merging fragmented or outdated data
Removing deleted or obsolete entries
Repacking data files into a more optimized format
Why Compaction Is Needed
Over time, due to updates, deletions, and inserts, storage systems accumulate stale data (e.g., overwritten or deleted keys), fragmented files, multiple versions of the same data.
Without compaction, this leads to increased storage usage (too many files and rows), slower read performance (data is spread across many files), memory pressure (querying too much data).
Where is Compaction Used?
Unsurprisingly, compaction is a widely used technique in systems where large volume of data is a norm. For example:
LSM Trees (Log-Structured Merge Trees): in databases like LevelDB, RocksDB, Cassandra
Data is written to immutable Sorted String Tables (SSTables) and periodically compacted into fewer, larger SSTables.
Columnar Formats: in file formats like Parquet, ORC
Compaction merges small files and reclaims space from deleted rows or updates.
Distributed File Systems: in large-scale systems like HDFS, Husky
Used to reduce the number of small files and optimize file layout.
Typical Steps in Compaction
Pick candidate files or data blocks (based on size, level, time, etc.)
Read and merge entries (typically k-way merge), resolving duplicates (e.g., keeping the latest version)
Remove tombstones (markers for deletions, for example, in Apache Cassandra)
Write back a compacted version to disk
Delete old, redundant files and update metadata
Compaction in Husky
During Ingestion, Husky ingests events and writes them into fragments (files) stored in object storage. Each fragment has metadata stored in FoundationDB, used to efficiently find relevant fragments during queries.
When a query is run:
Metadata is used to find relevant fragments.
Each fragment is scanned by a worker in parallel.
Results are merged.
As you can see, query cost depends on the number of fragments fetched and the number of rows scanned per fragment. Husky needs to optimize these two parameters.
The article contains a neat visualization of how compaction is done.
Fragment: Husky’s Native Storage Format
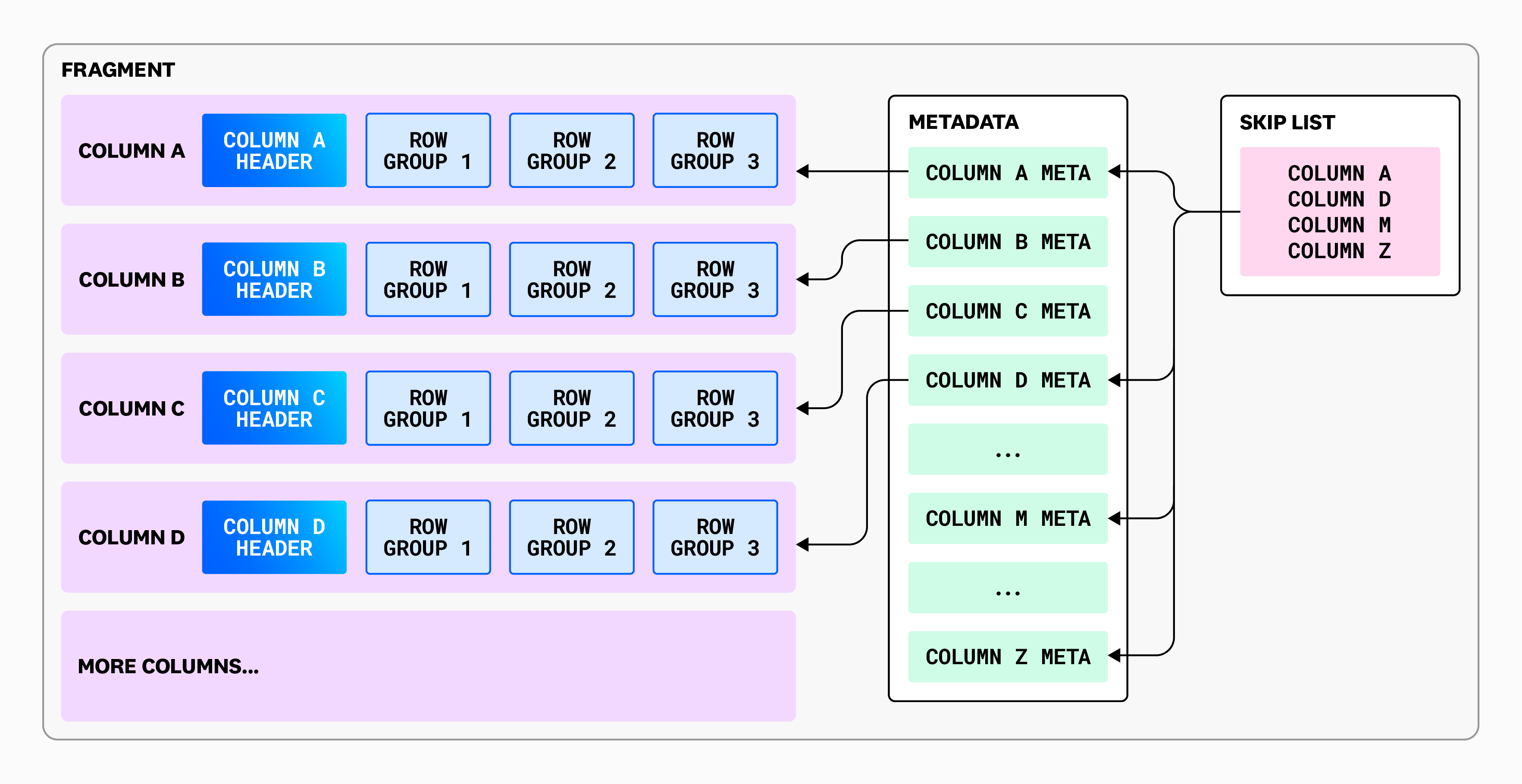
Fragment file storage format
The above diagram depicts the fragment format in Husky. Let’s quickly break it down:
A fragment is in columnar format.
Each column has a header and one or more row groups.
A row group contains the values of the particular column in those rows.
The row group size is limited so that memory consumption during compaction is bounded.
Each fragment can contain many columns.
There is metadata associated with each fragment.
A skip list is also used to search efficiently in the metadata, given that there can be even millions of columns in a fragment.
Because we don't control how customers send us their data, fragments must be able to support a huge variety of events, with individual tables containing data from any number of services. It’s not unusual for Husky to have fragments that, after compaction, contain hundreds of thousands (if not millions) of columns.
Design Considerations
To achieve performant compaction, Datadog came up with some solid design considerations. Let’s briefly discuss.
Row group size
Columns have row groups associated with it. The size of the row groups is chosen based on the maximum size of a column value for any column in a fragment. This ensures the row group doesn’t need more memory than a fixed upper bound while compacting or querying.
Time bucketing
In event storage, time is the single most ubiquitous data field. And for Datadog, given that it deals with metrics and logs, queries always have time column associated with them.
Husky splits the events not only in tables but also in time buckets. A fragment for a particular table contains events for a particular time window.
Size-tiered compaction
Husky uses a size-tiered compaction strategy, merging fragments into increasingly larger size classes.
Each merge operation creates a new fragment and atomically updates the metadata service by replacing old fragments. Over time, this yields large fragments of about a million rows, compared to the initial thousand-row fragments from the writer.
Sort schema
Husky optimizes query performance by avoiding scanning irrelevant rows, using predicates over tags like service or env to determine relevance.
To do this, it sorts rows using a defined set of important tags (e.g., service,status,env,timestamp) based on observed query patterns. Each fragment is sorted by a composite row key made from these fields, and the fragment’s header stores the sort schema along with its minimum and maximum row keys. This allows Husky to skip entire fragments that fall outside the lexical range of a query's target tag values.
The sorting and compaction process uses a log-structured merge (LSM) approach to handle the constant stream of incoming data efficiently.
Locality compaction
Husky uses locality compaction to produce fragments that are lexically narrow, which improves query pruning and efficiency.
After size-tiered compaction, new fragments enter level 0, and overlapping fragments determined by their row key ranges are merged to eliminate overlap. Each level has a row limit, and when exceeded, fragments are promoted to the next level, where the process continues.
Because fragment size stays constant while level capacity grows, higher-level fragments span smaller ranges of the lexical space, making them more likely to be pruned during queries.
This hybrid compaction strategy—combining size-tiered and locality compaction—enables Husky to balance write performance with efficient query execution.
Pruning
To optimize query execution, Husky uses fragment metadata to decide whether a fragment could contain relevant data for a query.
Instead of relying solely on row key ranges which become less effective when filtering on tags farther down the key, Husky builds finite-state automata for each sorted column.
These automatons, trimmed to reduce size, act like bloom filters: they accept all possible matching values without false negatives. The automata are transformed into regular expressions and stored in metadata, enabling fast filtering of irrelevant fragments during query planning. This method significantly improves query performance by reducing both the number of fragments fetched and the number of rows scanned.
I personally found this one quite interesting. While bloom filters are pretty common solution in this sort of existence checks, it also introduces false positives and more computation-heavy operations (i.e hashing). This is an example of showcasing how common problems can be solved more efficiently through careful observation of the behaviour of your data.
This is where I leave you today.
I personally found the article complex and interesting. There are definitely many details that Datadog didn’t share. Of course, it’s just an article and some details have to be left out. But overall, it was indeed an excellent article to learn how scalability comes with complex challenges.
So don’t forget to have a read. Cheers and see you in the next one! 🇵🇸
Reply