- Biweekly Engineering
- Posts
- High Throughput Systems: How to Handle Hot Rows | Biweekly Engineering - Episode 39
High Throughput Systems: How to Handle Hot Rows | Biweekly Engineering - Episode 39
How to handle hot rows in high throughput systems - from Google Cloud Community
Biweekly Engineering
May 29, 2025
Hot row contention occurs when a large number of updates target a small set of database records, causing locking conflicts and slowing down transactions. This issue, common in payment systems and beyond, can severely impact performance and business operations.
In today’s episode of Biweekly Engineering, we learn how to handle such hot rows in high-throughput systems. Later, we also discuss Optimistic Concurrency Control, a mechanism useful for high-throughput systems with low amount of concurrent transactions affecting the same rows in a database.
Let’s begin!

The famous Alhambra in Granada
Partnership with CodeCrafter!
Before jumping right into our today’s discussion, I am glad to announce that I now have a partnership with CodeCrafter - a platform where you can learn by actually building stuff from scratch. Unlike traditional platforms, CodeCrafter has challenges where you build things like Redis, Kafka or Git from scratch!

If this is how you are keen to learn, use the following link to get 40% discount on your subscription!

Real-world proficiency projects designed for experienced engineers. Develop software craftsmanship by recreating popular devtools from scratch.
Now that’s out of the way, let’s begin!
Handling Hot Rows in High-Throughput Systems

Hot Rows, Cool Solutions: Architecting for High-Throughput Payment Systems
Hot row contention occurs when multiple transactions attempt to update the same database row, resulting in locking delays. Even horizontally scalable databases can't avoid this if access patterns are skewed. This leads to queuing, like rush hour traffic funneling into a single lane. The impact includes higher latency, increased retries, and reduced throughput. Ultimately, it degrades system performance and frustrates users.
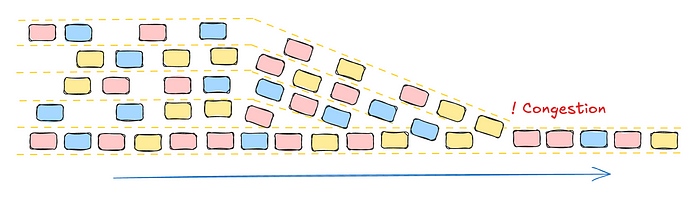
Strategies to Mitigate Hot Rows Contention
Append-Only Ledger Model: Prioritizing Writes
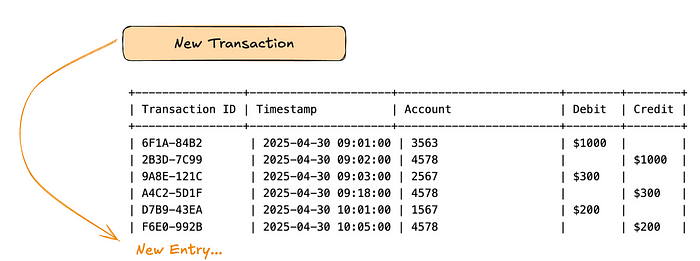
By appending new records instead of updating existing ones, this model allows concurrent writes without locking conflicts.
Every transaction is preserved as a separate entry, providing a complete and immutable history — ideal for financial compliance.
All write operations are basic inserts, reducing complexity and boosting throughput.
Current state (like balances) must be computed from historical entries, either on-demand (slower) or periodically (eventually consistent).
Ideal when write scalability and data integrity matter more than real-time balance reads.
Internal Sharding of Hot Accounts: Divide and Conquer
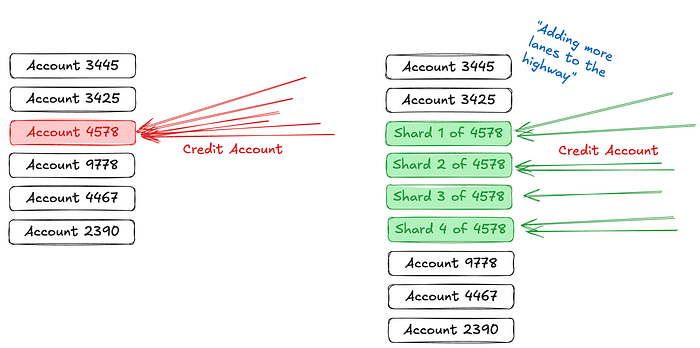
Splits a single hot account into multiple sub-accounts, spreading updates across rows to reduce lock contention.
Requires minimal schema modification; most complexity is handled in application logic.
By avoiding concentrated writes on one row, it significantly boosts concurrent write capacity.
Reading the full balance now involves querying and aggregating multiple sub-account rows.
Works well when contention is limited to a few known accounts, and the sharding strategy can be tuned accordingly.
Buffers and Batching: Absorbing the Spikes
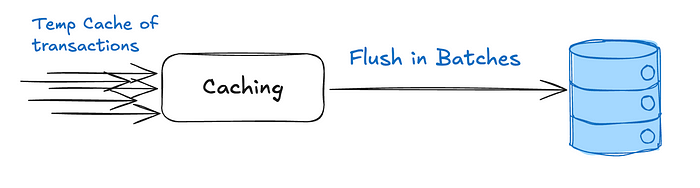
Incoming transactions are held in a fast in-memory or caching layer (e.g., Redis) before being written to the database in batches.
Consolidating multiple updates into fewer writes lessens lock competition and improves efficiency.
Allows transactions to be merged or pre-processed (e.g., summing debits) before reaching the database.
If the buffer crashes without persistence, unflushed transactions may be lost unless recovery mechanisms are in place.
Best when maximizing system throughput is more critical than immediate durability or real-time persistence.
Event-Driven Architecture (CQRS): Ultimate Separation of Concerns
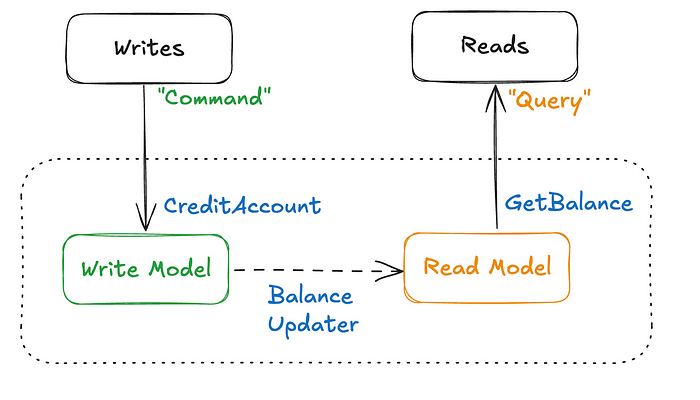
Writes (commands) are stored as immutable events, while reads use denormalized, query-optimized models updated asynchronously.
Appending events for writes avoids row-level locking, and reads don’t compete with writes for the same data structures.
Write and read workloads can be scaled and optimized separately, enabling high performance and flexibility.
Read models lag behind writes, requiring careful handling of consistency and user expectations.
Ideal when scalability, resilience, and flexibility outweigh the increased architectural and operational complexity.
Be Careful! Consider Optimistic Concurrency Control
Optimistic Concurrency Control (OCC) is a concurrency control method that assumes that multiple transactions can frequently complete without interfering with each other.
In an OCC environment, transactions proceed without acquiring locks on data items. Instead, they check for conflicts only when they attempt to commit. If a conflict is detected, the transaction is typically rolled back and retried. This approach can lead to higher throughput in systems with low contention, as it avoids the overhead of locking.
So it’s crucial that you consider OCC for your system. It might be just enough to use OCC!
I have personally worked on systems that used OCC on high-throughput environment. Let’s learn a bit more about it.
How Optimistic Concurrency Control Works
OCC typically involves three phases for each transaction:
Read Phase (or Working Phase): The transaction reads data items and records the changes locally. It doesn't acquire any locks. For each item read, the transaction also records its version number or a timestamp.
Validation Phase: Before committing, the transaction checks if any of the data items it read or modified have been changed by another concurrently committed transaction since it began its read phase. This is the crucial step where conflicts are detected.
Write Phase: If the validation phase is successful (no conflicts detected), the changes are made permanent in the database. If validation fails, the transaction is aborted and retried.
When to Use Optimistic Concurrency Control
OCC is particularly well-suited for:
Low Contention Environments: When the likelihood of two transactions trying to modify the same data concurrently is low.
Read-Heavy Workloads: As reads don't acquire locks, they are very fast.
Systems where rollbacks are acceptable: If the cost of retrying a transaction is less than the overhead of acquiring and releasing locks.
Disadvantages of Optimistic Concurrency Control
Higher Abort Rate in High Contention: If many transactions try to modify the same data, the validation phase will frequently fail, leading to many aborted transactions and wasted work.
Complexity: Implementing OCC correctly can be more complex than traditional locking mechanisms.
Starvation: In extreme cases of high contention, a transaction might repeatedly fail validation and never commit.
Implementing Optimistic Concurrency Control in Go
Let's illustrate OCC with a simple example in Go. We'll simulate a banking system where users have accounts, and we want to perform transfers between them. Each account will have a version number to track changes.
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
// Representing a simple bank account
type Account struct {
ID int
Value int64
Version int64 // Used for Optimistic Concurrency Control
}
// In-memory database with a single account for simplicity
type DataStore struct {
account *Account
mu sync.RWMutex
}
func NewDataStore(id int, initialValue int64) *DataStore {
return &DataStore{
account: &Account{
ID: id,
Value: initialValue,
Version: 0,
},
}
}
// Returns a copy of the account
func (ds *DataStore) ReadAccount() (*Account, int64) {
ds.mu.RLock()
defer ds.mu.RUnlock()
currentVersion := atomic.LoadInt64(&ds.account.Version)
return &Account{
ID: ds.account.ID,
Value: ds.account.Value,
Version: currentVersion,
}, currentVersion
}
/* AttemptUpdate simulates the commit phase with OCC validation. */
func (ds *DataStore) AttemptUpdate(modifiedAccount *Account, expectedVersion int64) error {
ds.mu.Lock()
defer ds.mu.Unlock()
/* Validation Phase */
if atomic.LoadInt64(&ds.account.Version) != expectedVersion {
return fmt.Errorf("OCC conflict: version mismatch for Account %d (expected %d, got %d)",
modifiedAccount.ID, expectedVersion, atomic.LoadInt64(&ds.account.Version))
}
/* Write Phase */
ds.account.Value = modifiedAccount.Value
atomic.AddInt64(&ds.account.Version, 1)
return nil
}
// SimulateTransaction performs a simple operation on the account using OCC.
func SimulateTransaction(ds *DataStore, txID int, delta int64) {
fmt.Printf("Tx %d: Starting transaction.\n", txID)
// Read Phase
accountCopy, readVersion := ds.ReadAccount()
fmt.Printf("Tx %d: Read Account (ID: %d, Value: %d, Version: %d)\n",
txID, accountCopy.ID, accountCopy.Value, readVersion)
// Simulate some work being done with varying delays
time.Sleep(time.Duration(txID%50) * time.Millisecond)
accountCopy.Value += delta
fmt.Printf("Tx %d: Local change - new value %d\n", txID, accountCopy.Value)
// Validation and Write Phase: Attempt to commit.
err := ds.AttemptUpdate(accountCopy, readVersion)
if err != nil {
fmt.Printf("Tx %d: Transaction FAILED - %v. (Needs retry in a real system)\n", txID, err)
} else {
fmt.Printf("Tx %d: Transaction SUCCESS! New Account Value: %d, Version: %d\n",
txID, ds.account.Value, ds.account.Version)
}
}
func main() {
ds := NewDataStore(1, 100) // Our single account, starting at 100
fmt.Println("Initial State:")
acc, ver := ds.ReadAccount()
fmt.Printf("Account ID: %d, Value: %d, Version: %d\n\n", acc.ID, acc.Value, ver)
var wg sync.WaitGroup
numTransactions := 3 // Number of concurrent transactions
// Launch multiple goroutines, all trying to modify the same account.
for i := 0; i < numTransactions; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
SimulateTransaction(ds, id, 10) // Each transaction tries to add 10
}(i + 1) // Start transaction IDs from 1
}
wg.Wait()
fmt.Println("\nFinal State:")
acc, ver = ds.ReadAccount()
fmt.Printf("Account ID: %d, Value: %d, Version: %d\n", acc.ID, acc.Value, ver)
}The code can be run and played with on Go Playground!
Even if you are not familiar with Go, it should be pretty easy to read. The implementation above is a very simple demonstration for OCC. Basically, 3 transactions concurrently try to execute but one of them succeeds and the other two fails. Example output:
Initial State:
Account ID: 1, Value: 100, Version: 0
Tx 3: Starting transaction.
Tx 3: Read Account (ID: 1, Value: 100, Version: 0)
Tx 1: Starting transaction.
Tx 2: Starting transaction.
Tx 2: Read Account (ID: 1, Value: 100, Version: 0)
Tx 1: Read Account (ID: 1, Value: 100, Version: 0)
Tx 1: Local change - new value 110
Tx 1: Transaction SUCCESS! New Account Value: 110, Version: 1
Tx 2: Local change - new value 110
Tx 2: Transaction FAILED - OCC conflict: version mismatch for Account 1 (expected 0, got 1). (Needs retry in a real system)
Tx 3: Local change - new value 110
Tx 3: Transaction FAILED - OCC conflict: version mismatch for Account 1 (expected 0, got 1). (Needs retry in a real system)
Final State:
Account ID: 1, Value: 110, Version: 1
And that’s where I leave you for today. Hope to see you all soon with the next episode of Biweekly Engineering!
Until then, stay awesome! 💪
Reply