- Biweekly Engineering
- Posts
- LLM Systems at Scale | Biweekly Engineering - Episode 31
LLM Systems at Scale | Biweekly Engineering - Episode 31
Today's LLM application architecture from Github | How Discord builds LLM-driven systems
Biweekly Engineering
June 06, 2024
Good greetings to the 31st episode of Biweekly Engineering! Excited for another day of learning something new? Me too!
In today’s episode, I have two different blog posts to feature and guess what, both of them are about LLMs:
How the architecture of today’s LLM apps look like from Github Engineering
And from Discord: how to rapidly develop using LLMs
Let’s go! 🦙

Inside the ancient Roman Colosseum
Architecture of LLM Apps
Not so long ago, ChatGPT took over the world by storm.
It’s not even an understatement to say that the release of ChatGPT in November 2022 changed the landscape of tech forever!
Since then, LLMs have become a new norm, and numerous LLMs have been released - from open source ones, like LLaMA by Meta to commercial ones, like Google Bard/Gemini (whatever they are calling it right now).
The good thing about LLMs is that you can use them as off-the-shelf solutions.
Building and training LLMs is a resource consuming process. It doesn’t really make sense for everyone to build their own LLMs from scratch. Rather, the smart thing to do is to use a ready-made solution (or take one and fine tune it).
And this is where the article from Github comes into use. It gives us a clear overview (doesn’t go deep, of course) of how today’s LLM architectures look like.
At a super high level, there are 5 steps to build an LLM app:
Landing on the problem you want to solve
Choosing the right LLM from numerous LLMs available right now
If required, customizing the pre-trained LLM to solve the specific problem you are working on
Setting up the architecture of the whole end-to-end system that solves the problem
Evaluating how the LLM is performing in production
But how does the architecture look like?
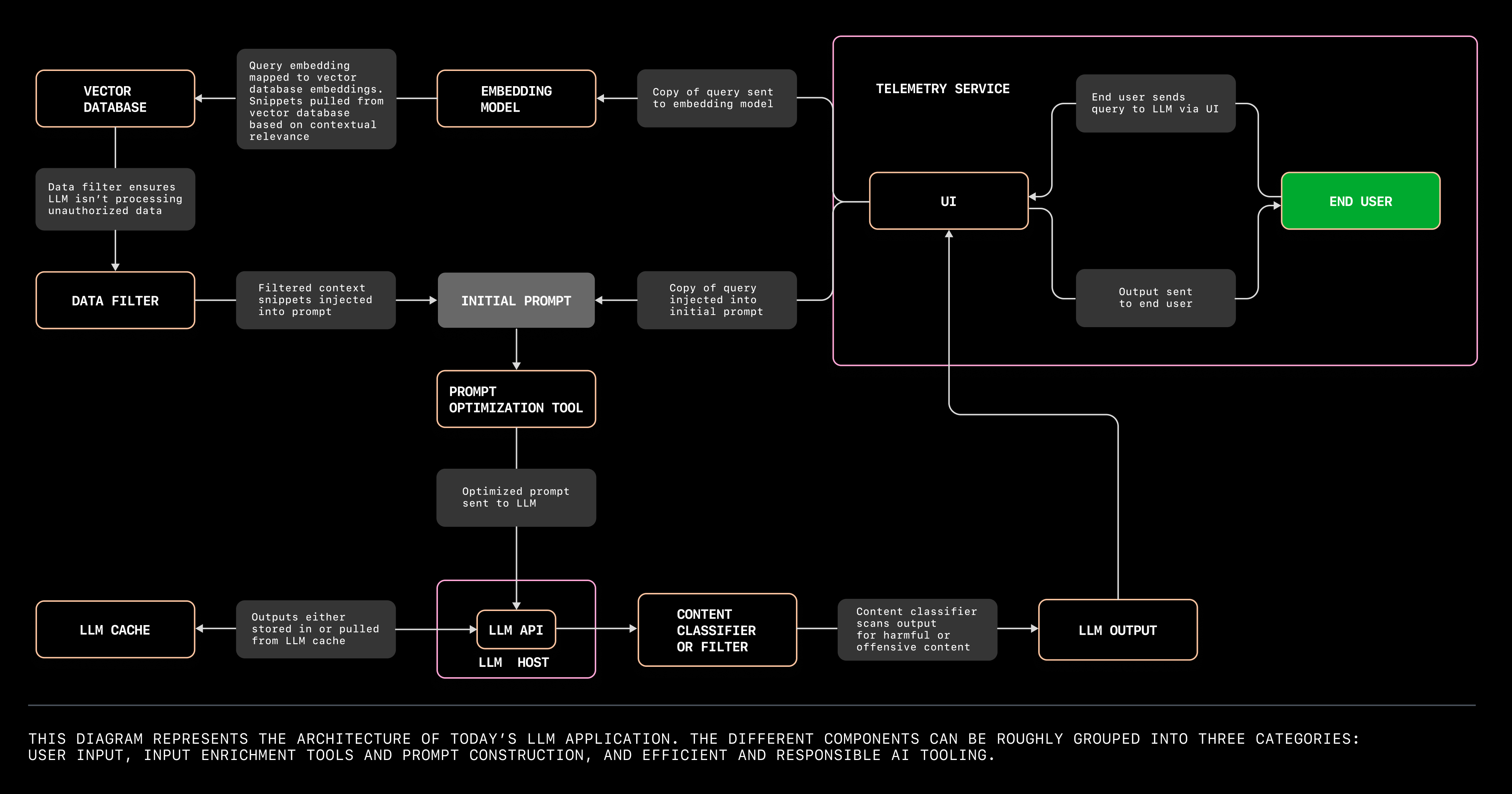
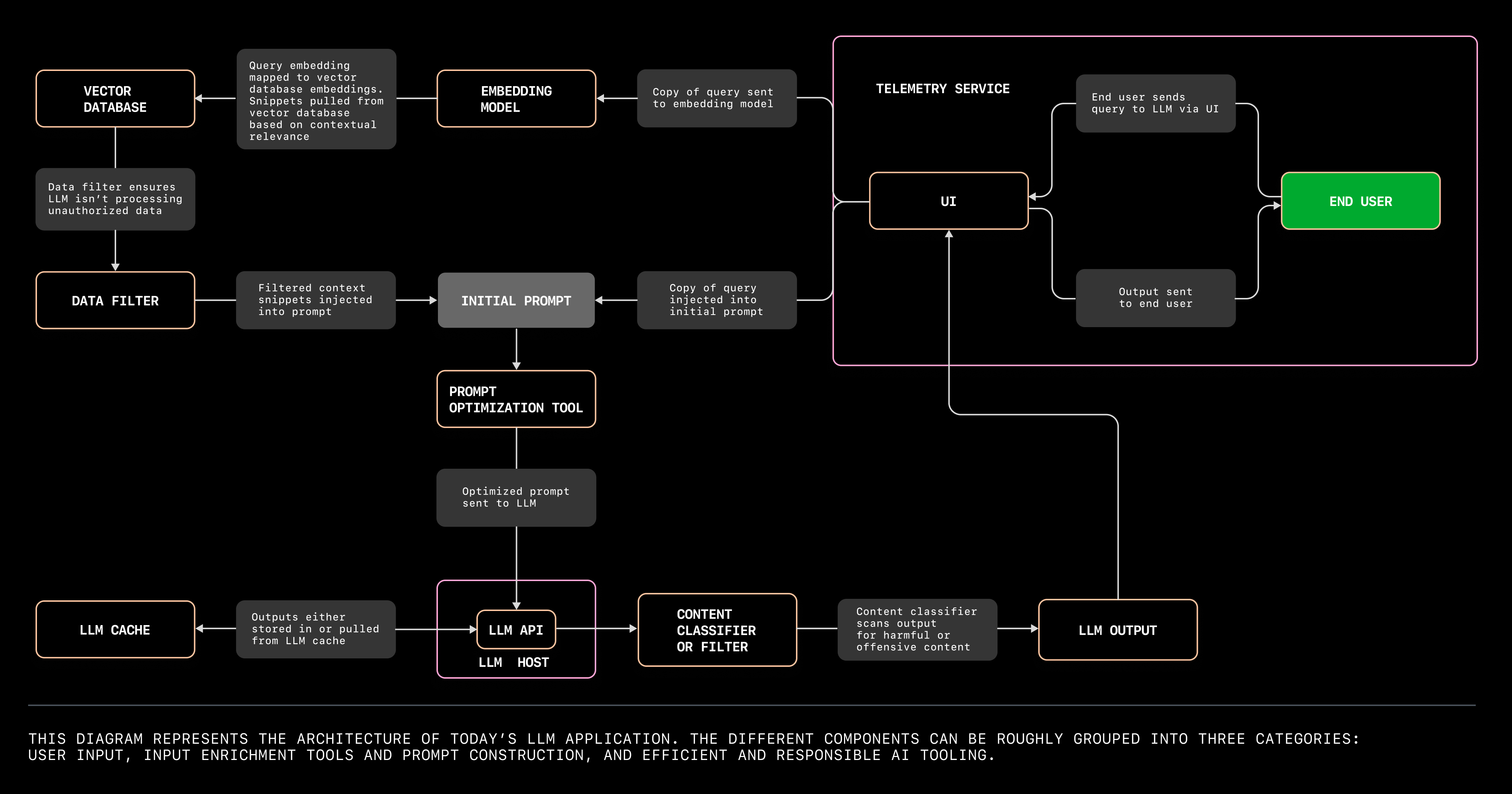
From Github blog
The diagram above showcases the big chunks of an LLM-based application architecture. Let’s briefly discuss:
The first group we need is user input tools. It generally includes UI, API hosts, and sometimes speech-to-text translation tool.
The next group is the mechanism of enriching and contextualizing the input. It’s not always enough to send the plain user input to the LLM. There might be some sort of context injected to it. The article provides an example that I highly recommend you to check it out.
The last group is efficient and responsible components in the architecture. This is the part where we need to build for efficiency (LLM cache, telemetry service) and responsibility (content classifier to prevent harmful content).
As the diagram shows, input from users are sent to an embedding model to inject contexts, which is then fed into the LLM API. The API checks with LLM cache, sends the output through content filter, and then sends the output.
Developing Rapidly with Generative AI at Discord

How does Discord develop using Generative AI? In this article, we get a high-level overview of the process Discord follows. Let’s break it down:
Identify the use case for Generative AI - does discord really need Generative AI for a particular problem in hand?
Define the product requirements - define the expected latency, QPS, prompt length, safety and quality requirements, etc.
Prototype the AI applications - this stage involves steps like selecting the right LLM to use and evaluating the performance of the LLM.
Launch and learn - the final stage is to launch the application and monitor live to understand its performance and improvement scopes.

From Discord blog
The above diagram shows how an LLM application is deployed. This is definitely very high-level and doesn’t depict all the components.
As the diagram shows, the major block is the LLM Inference Server which infers from the user input and produces the output. Then there is the Content Safety Service which basically sanitizes the output and sends it back to the user.
Of course, the devil is in the details. Discord doesn’t explain the full process end-to-end in detail, rather gives us an overview. But the article explains how LLM apps are developed in the industry, which is definitely something we can take away.
Okay. That’s a wrap for today. This episode surely helped me learn new stuff! I work as a backend engineer - venturing into the wild west of AI and LLMs was indeed interesting. Don’t miss the fun, specially if you are like me!
Adios y hasta luego! ✋
Reply