- Biweekly Engineering
- Posts
- Storing Trillions of Messages at Discord - Biweekly Engineering - Episode 11
Storing Trillions of Messages at Discord - Biweekly Engineering - Episode 11
How Discord migrated to ScyllaDB to optimise storage for trillions of messages, plus two interesting articles from Facebook and PayPal
Biweekly Engineering
April 13, 2023
Greetings dear esteemed readers! Welcome back to the 11th episode of Biweekly Engineering!
In today’s episode, I have three beautiful blog posts to share with you:
Asynchronous computing at Facebook
Storing trillions of messages at Discord
Beginning of GraphQL at PayPal
Let’s dive straight into it!The famous number 12 tram in Lisbon under the crescent moon

The famous number 12 tram in Lisbon under the crescent moon 🌛
Asynchronous computing at Facebook
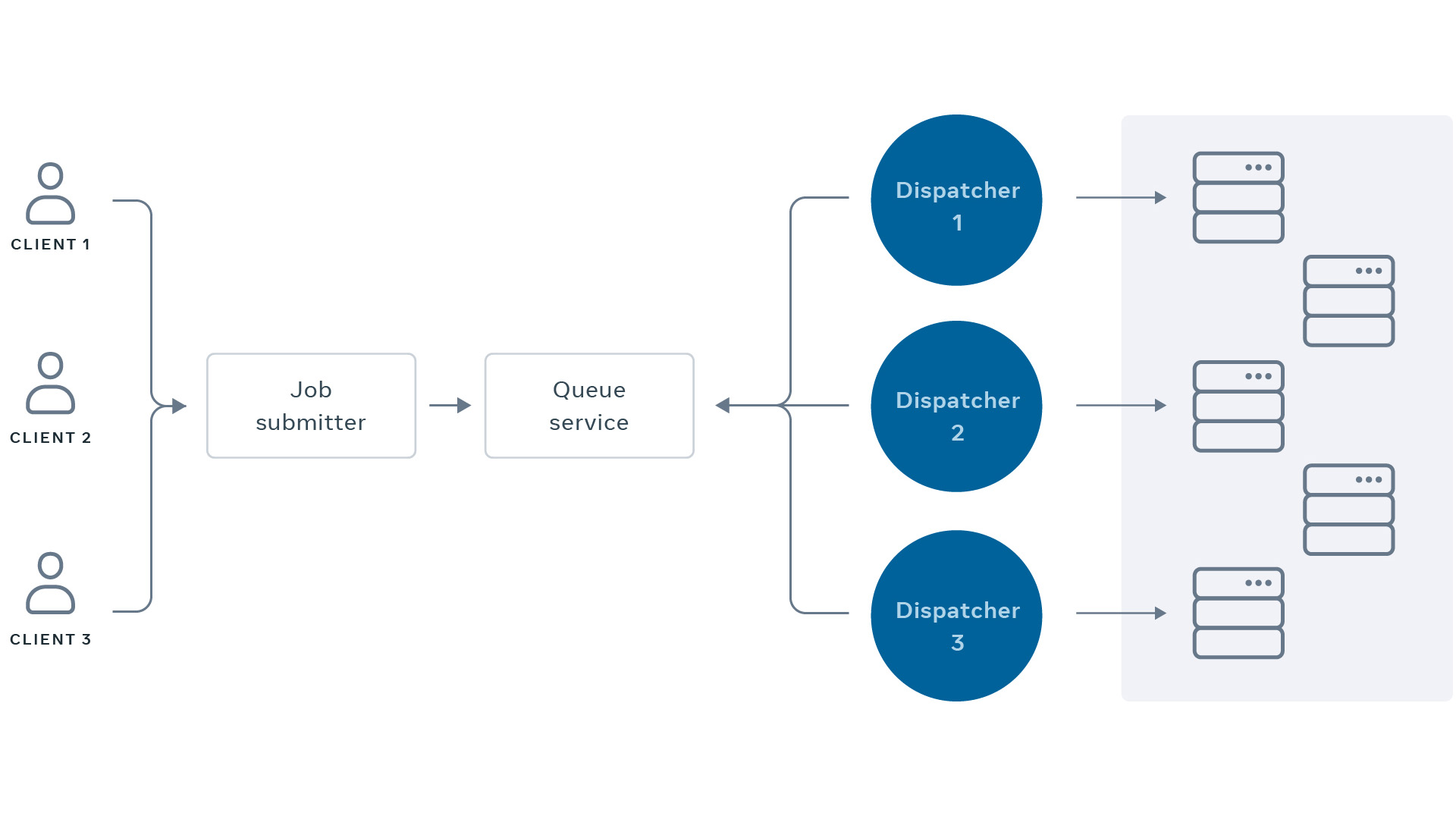
#meta #facebook #asynchronous #distributedsystems
At Facebook, asynchronous requests are used for a myriad of use cases. But how to execute these requests at scale?
There are two versions of the system discussed in the article.
In the first version, all the requests were persisted in a central database. Then there were dispatcher services which queried the database to select a bunch of requests, sorted them based on priority, and sent them to workers. These workers performed the actual execution.
As the above solution started to show issues with higher scale, the team needed to build the next version of the system. There were couple of challenges to address-
Prioritisation - which asynchronous request should get higher priority?
Capacity optimisation - how to optimise the computational capacity so that machines are well-utilised?
Capacity regulation - how to make sure that capacity is well-distributed?
The article discussed how the team approached to resolve the challenges and build the system to achieve higher scale.
Beginning of GraphQL at PayPal
#paypal #graphql
GraphQL is currently a widely used technology in the industry. It reduces the complexity of client-server communication, specially in systems where clients need to fetch data from multiple services to serve users.
Furthermore, GraphQL enables clients to request and retrieve precisely the data they require. In REST, clients receive all the data returned by an endpoint, whether it's needed or not. Conversely, GraphQL empowers clients to be selective about their needs.
If you are not familiar with GraphQL, this is a wonderful starting point:

For PayPal, the team was facing the typical challenges that large systems encounter with REST. This is why they decided to search for a solution to address the pain points of REST, and they discovered GraphQL.
Originally developed at Facebook, GraphQL was later open-sourced for the community. Currently, numerous systems worldwide utilize this helpful technology.
As the article highlights, adopting GraphQL for PayPal's checkout was only the beginning. More teams began to embrace it, and it rapidly gained momentum at PayPal.
Storing trillions of messages at Discord

#discord #cassandra #scylladb
Read about the incredible engineering feat of storing trillions of messages at Discord!
This particular post has been gaining a lot of attention lately, and it's no wonder why, considering the impressive achievement the article details.
In the previous episode of Biweekly Engineering, I shared the earlier story of storing billions of messages at Discord. You can find the article here-

Discord started its journey using MongoDB as the storage for its messages. However, the platform quickly expanded, making it challenging for engineers to continue using MongoDB. After a comprehensive assessment, the team opted to use Cassandra, a widely-used NoSQL database.
But as Discord kept growing, Cassandra began exhibiting signs of wearing out. Engineers were consistently battling the hot partition issue, in which a particular partition would receive an excessive amount of traffic, causing a latency spike for requests attempting to query that partition. The situation was only deteriorating.
Discord attempted to alleviate the system's load by using an intermediary system called data services. This system sits between their API monolith and the database cluster, coalescing the same requests and reusing the response instead of querying the database every time for each one. This decreased the load, but the problem persisted.
Then ScyllaDB came into the picture, and Discord decided to migrate from Cassandra to ScyllaDB.
ScyllaDB, a highly performant database that bills itself as a drop-in replacement for Cassandra, is written in C++, unlike Cassandra, which is written in Java. This immediately brings the advantage of no garbage collection, which is a slow process that hinders performance.
In the end, the results of this effort were tremendous, as pointed out in the article:
…we’re going from running 177 Cassandra nodes to just 72 ScyllaDB nodes. Each ScyllaDB node has 9 TB of disk space, up from the average of 4 TB per Cassandra node.
Our tail latencies have also improved drastically. For example, fetching historical messages had a p99 of between 40-125ms on Cassandra, with ScyllaDB having a nice and chill 15ms p99 latency, and message insert performance going from 5-70ms p99 on Cassandra, to a steady 5ms p99 on ScyllaDB.
With that, I am wrapping up this week’s episode. Squeeze out some time from your busy schedule to read the articles, and don’t forget to recommend the newsletter to your peers! This is the link to subscribe: https://biweekly-engineering.beehiiv.com/subscribe
See you all soon enough! :)
Reply