- Biweekly Engineering
- Posts
- Text-to-SQL: An Exquisite LLM Use-Case from the Industry | Biweekly Engineering - Episode 36
Text-to-SQL: An Exquisite LLM Use-Case from the Industry | Biweekly Engineering - Episode 36
Suddenly, everyone is building text-to-SQL solutions!
Biweekly Engineering
December 06, 2024
If you don’t live under a rock, you know ChatGPT and LLMs. They have essentially changed the world. Now, every company is trying hard to use LLMs to solve any suitable problem they have. Yes, building LLM-based solution is the new coolness!

The hot air balloon ride over Cappadocia, Turkiye
Today, we have two articles from two different companies that solved the same problem: text-to-SQL using LLMs. It is a fine example of how LLMs can increase developer productivity.
Text-to-SQL Solution at Swiggy
Just like every modern startups and tech companies, Swiggy is a data-driven company. Every data-driven company needs answers for many different analytical queries on top of the data they have. So if there is an AI writing the queries quickly and correctly for them, it is a win!
“What was the average rating last week in Bangalore for orders delivered 5 mins earlier than promised?”
Enter Hermes V1
Hermes, the text-to-SQL solution at Swiggy was developed through 2 iterations.
In the first version, users bring their own metadata, type it in a prompt, and pass it to an LLM. Then the LLM builds the query, executes it, and returns the result.
Why Reinvent the Wheel?
Swiggy's initial performance assessments compared their implementation with industry solutions but found that their users' complex queries required a tailored approach.
The vast volume of data and unique business contexts, such as differences between Food Marketplace and Instamart metrics, highlighted the limitations of a one-size-fits-all solution. To address this, they restructured their approach by compartmentalizing Hermes into distinct business units called charters, each tailored to specific business needs and data sources.
These charters have their own metadata and address use cases unique to their domain. Despite early challenges, Swiggy gained confidence in Hermes' ability to improve productivity and democratize data access.
Hermes V2
The diagram above summarizes Hermes V2 pretty well.
User Interface: Slack serves as the entry point where users input prompts and receive SQL queries and their outputs.
Middleware: AWS Lambda acts as an intermediary, handling communication between the UI and the Gen AI model while preprocessing inputs.
Gen AI Model: Databricks runs a job to fetch the charter-specific GenAI model (GPT-4o), generates and executes the SQL query, and returns the results.
Of course, the above is a high-level design. The article goes further and explains how the third piece, the GenAI model pipeline works.
Pinterest’s Text-to-SQL Solution
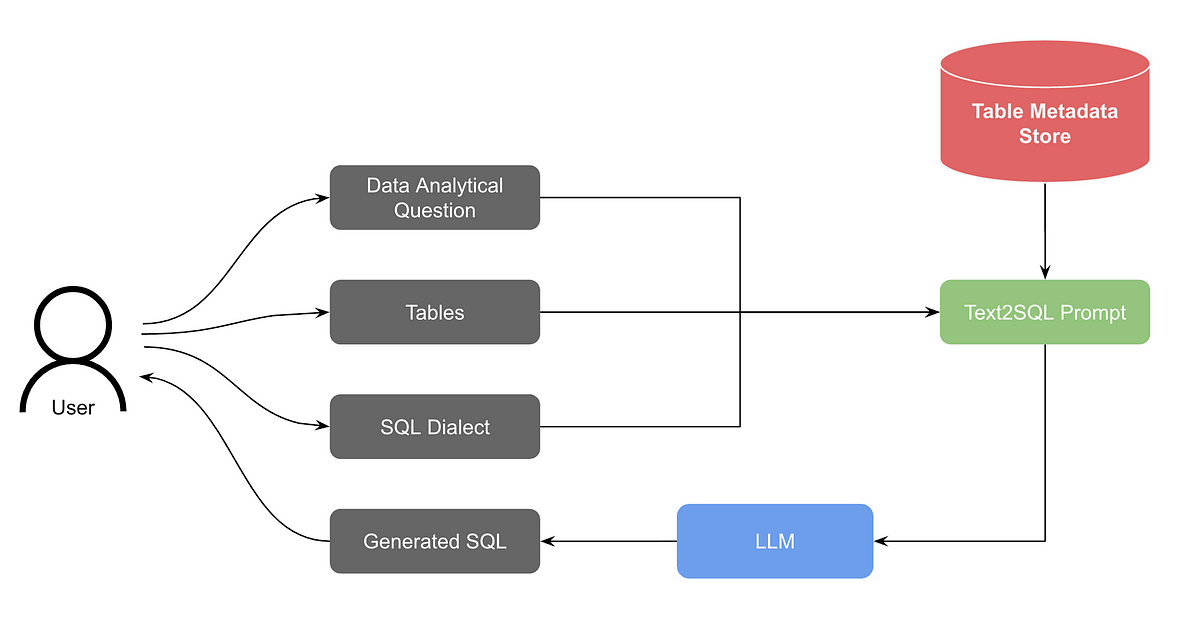
This brings us to the next article for today’s episode. Pinterest also built a text-to-SQL solution from scratch.
A Humble Beginning
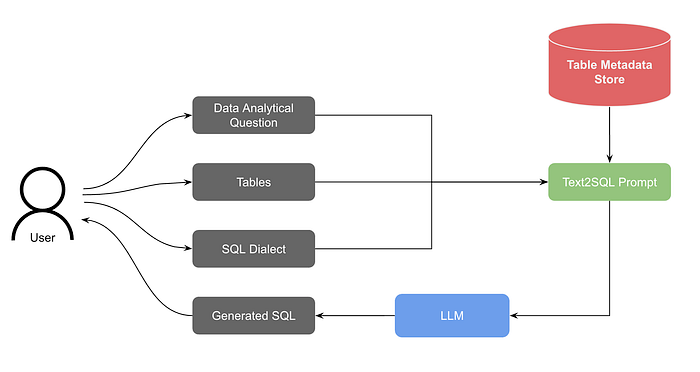
As usual, the initial iteration for the system was simpler. As mentioned in the article:
The relevant table schemas are retrieved from the table metadata store.
The question, selected SQL dialect, and table schemas are compiled into a Text-to-SQL prompt.
The prompt is fed into the LLM.
A streaming response is generated and displayed to the user.
In the table metadata store, it’s important to provide enough information explaining table, each column, and potentially enum values if a column only has enums.
Here is how the prompt looks like! 👇️
prompt_template = """
You are a {dialect} expert.
Please help to generate a {dialect} query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
===Tables
{table_schemas}
===Original Query
{original_query}
===Response Guidelines
1. If the provided context is sufficient, please generate a valid query without any explanations for the question. The query should start with a comment containing the question being asked.
2. If the provided context is insufficient, please explain why it can't be generated.
3. Please use the most relevant table(s).
5. Please format the query before responding.
6. Please always respond with a valid well-formed JSON object with the following format
===Response Format
{{
"query": "A generated SQL query when context is sufficient.",
"explanation": "An explanation of failing to generate the query."
}}
===Question
{question}
"""
Pinterest gave us a glimpse of how much the initial iteration helped in terms of productivity.
In our real world data, we find a 35% improvement in task completion speed for writing SQL queries using AI assistance.
RAG-Based Solution
Just like Swiggy, Pinterest also built a second version of the system which added RAG support to the system.
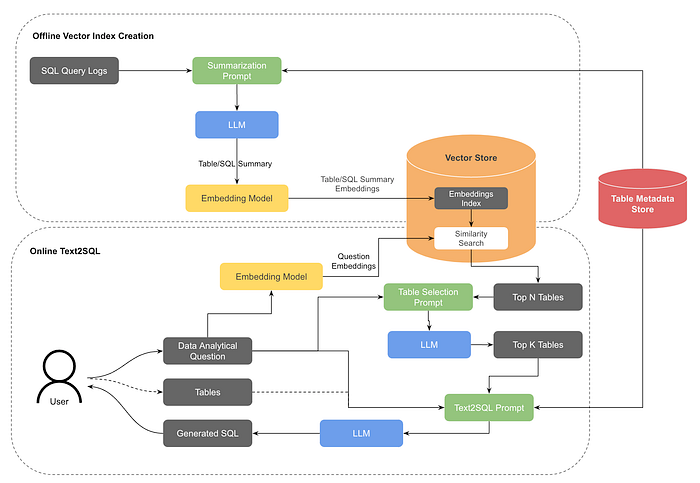
We can summarize the architecture shown in the diagram:
Initial Challenge: Users struggled to identify appropriate tables from hundreds of thousands in the data warehouse, even when Version 1 performed adequately with user-provided table information.
RAG Integration: Retrieval Augmented Generation (RAG) was implemented to assist users in selecting relevant tables for their tasks.
Offline Vector Index Creation:
A vector index is generated using table summaries and historical query data.
Only top-tier tables are indexed to ensure high-quality datasets.
Table summaries are created using table schemas and sample queries, processed by an LLM, and stored as embeddings in a vector store.
Table and Query Summarization:
Table summaries describe table contents, schemas, and use cases.
Query summaries capture query purposes and associated tables, with embeddings stored in OpenSearch for similarity search.
Table Search Process:
User questions are converted to embeddings and matched against table and query vector indices.
Table summaries are weighted more heavily than query summaries in scoring.
Table Re-selection:
An LLM evaluates the top N tables and selects the top K most relevant ones for user validation.
User-confirmed tables are used in the Text-to-SQL pipeline and for general table searches in Querybook.
Utility: The NLP-based table search enhances both analytical question handling and general table search functionalities.
While the above gives a summary of the architecture, I highly recommend my readers to read the complete article!
Addendum
To readers who are not very familiar with vector embeddings or RAG, here are two resources for you:

Enjoy learning! 👋
Reply